


最新Web
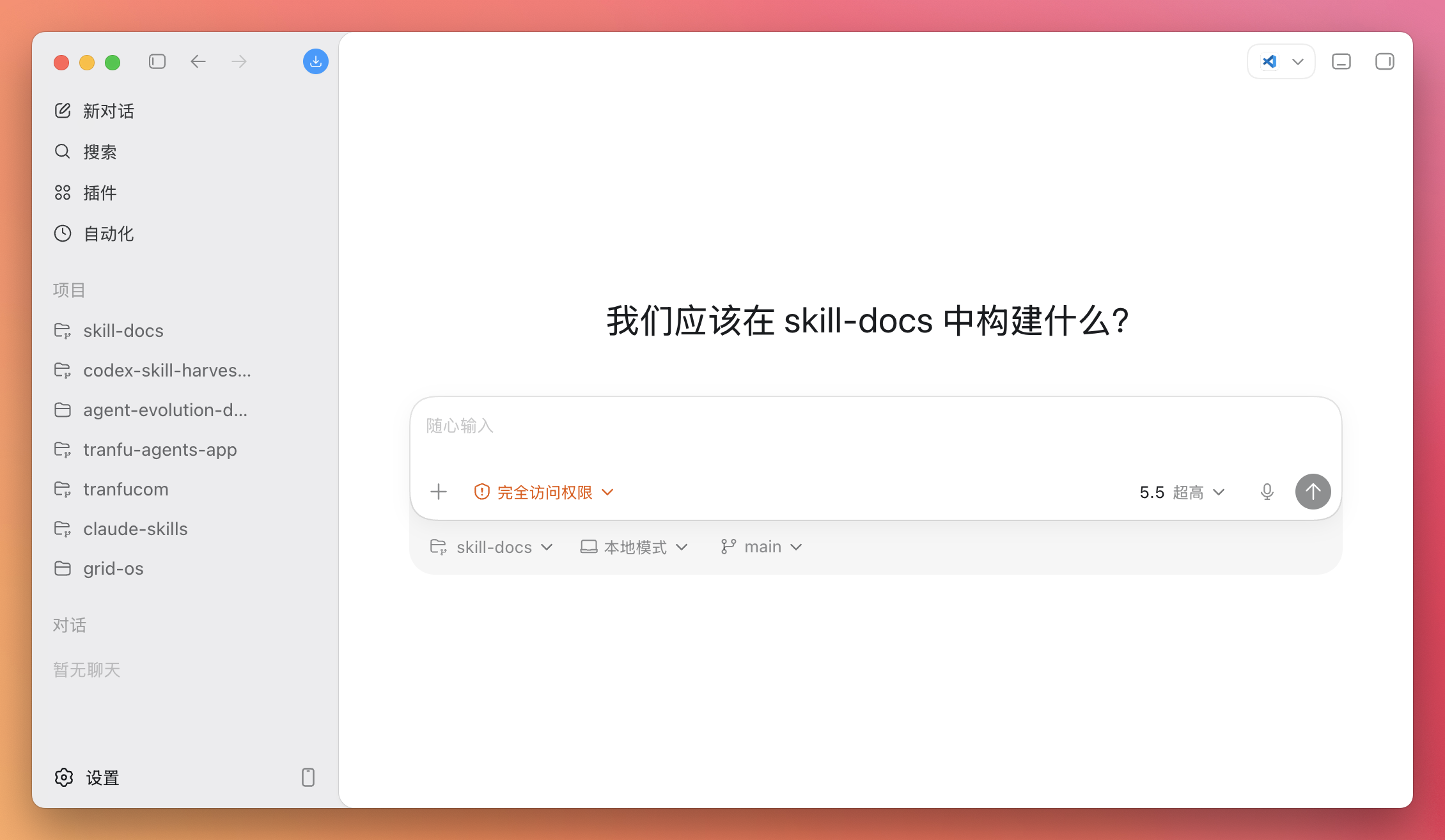
项目看板
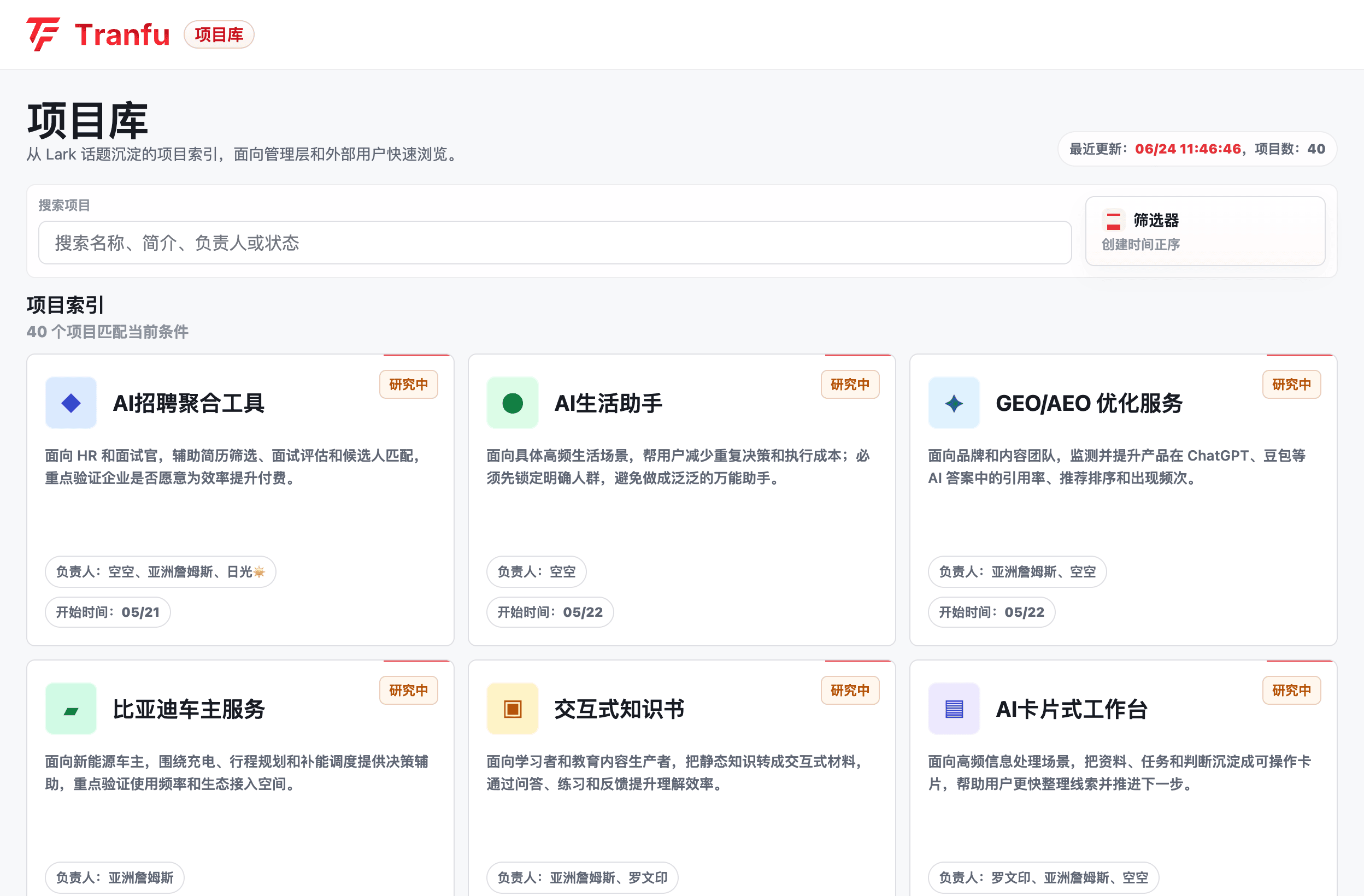
查看项目名称、简介、负责人和当前状态的项目看板,支持搜索、负责人筛选、状态视图和卡片/列表切换。
真实项目搜索和负责人筛选研究中、开发中、已完成状态视图产品卡片、紧凑列表和状态看板
把重复执行交给 Agent,把创造与决策留给你
查看项目名称、简介、负责人和当前状态的项目看板,支持搜索、负责人筛选、状态视图和卡片/列表切换。
查看项目名称、简介、负责人和当前状态的项目看板,支持搜索、负责人筛选、状态视图和卡片/列表切换。
一站式图片处理与自动化工具平台,支持图片压缩、格式转换、清晰度增强、添加水印,并持续扩展 API 与 CLI 能力。
从十五五政策叙事到资金流分支,再到个股候选的量化研究工作台。
把固定 JD 转成岗位 Agent,用统一标准评估简历和作品集,输出分数、档位、优劣势、风险点和面试问题。

312 次下载
把复杂 Build / Design 目标拆成目标文档、用户画像、阶段设计与验证闭环,帮助项目从模糊需求走向清晰执行。
248 次下载
通过工程 Checklist 反复审查 Prompt、Skill 与 Agent 定义,定位问题并持续优化,直到结果收敛。
186 次下载
判断一段经验、规则或复盘是否适合沉淀为 Codex Skill,并指出缺失信息与优化方向。
152 次下载
将复盘或 Guardrail 抽象成清晰任务域,明确命名、边界、适用场景与验收标准。
118 次下载
为 Lark、Slack、微信等分享场景配置标题、描述、Icon 与卡片图,提升分享展示效果。
94 次下载
通过禁区清单、评分维度与诊断问题,快速判断一个 AI 创业方向是否值得继续推进。




获取产品更新、Skill 资源、实战案例与 AI Agent 共创机会.
| 组件 | 定位 | 核心能力 |
|---|---|---|
| Claude Code | Anthropic 官方本地 AI 编程助手 | 读写代码、执行 Shell、操作 Git、处理复杂工程任务 |
| OpenClaw | 本地 AI Gateway + 渠道中枢 | 连接 Telegram/飞书/Discord、调度多种 AI 模型、集成飞书/日历/Gmail 等 tools |
通过手机/电脑上的 Telegram 或 飞书,向 OpenClaw 发送指令。
OpenClaw 收到后,可以启动真正的 Claude Code CLI 作为子进程(通过 ACP 协议),让 Claude 在 Mac 上执行大型编程任务,完成后把结果返回到聊天窗口。
[你] → Telegram / 飞书
↓
[OpenClaw Gateway] ← 本地运行 (127.0.0.1:18789)
↓
┌─────┴─────┐
│ │
飞书操作 ACP 子进程
│ │
lark-cli [Claude Code]
│ │
文档/Base 代码/Shell/Git发送以下命令:
/acp spawn claude --bind here效果:
~/.openclaw/workspace-claude 下工作在支持话题/线程的渠道(如飞书群、Discord):
/acp spawn claude --mode persistent --thread auto效果:
/acp spawn claude --mode oneshot效果:
| 命令 | 作用 |
|---|---|
/acp status |
查看当前聊天的 ACP 绑定状态 |
/acp cancel |
取消当前正在执行的任务 |
/acp close |
关闭 ACP 会话并解绑 |
/acp doctor |
检查 ACP 系统健康状态 |
当 Claude 被 OpenClaw 通过 ACP 启动后,Claude 并不直接拥有飞书 tools。飞书操作由 OpenClaw 的 main agent 或内置 skills 执行。
但你可以这样配合:
步骤 1:在 Telegram 里绑定 Claude
/acp spawn claude --bind here步骤 2:给 Claude 派活
帮我写一份今天的研发进度日报,包含:
- 已完成:修复了登录 bug
- 进行中:重构订单模块
- 阻塞项:等待设计稿Claude 生成内容后返回给你。
步骤 3:把内容发给 OpenClaw 的 main agent
把下面这份日报发到飞书群 [已脱敏]:
[粘贴 Claude 生成的内容]OpenClaw(main agent)会调用飞书工具完成发送。
OpenClaw 连接的飞书应用是 Clawdbot(appId: [已脱敏])。所有通过 OpenClaw 或 lark-cli 执行的飞书操作,默认都以这个 Bot 的租户身份进行。
{
"appId": "[已脱敏]",
"brand": "feishu",
"defaultAs": "bot",
"identity": "bot"
}测试命令结果:
lark-cli im +chat-search --query test --as bot --page-size 1
# -> { "ok": true, "identity": "bot" }| 操作 | 示例命令/指令 |
|---|---|
| 发送文本消息 | @bot 发送消息到群 [已脱敏]:今天进度更新 |
| 发送 Markdown | @bot 用 markdown 发飞书消息... |
| 搜索群聊 | lark-cli im +chat-search --query xxx --as bot |
| 查看历史消息 | lark-cli im +chat-messages-list --chat-id [已脱敏] |
| 操作 | 示例命令/指令 |
|---|---|
| 创建文档 | @bot 在飞书里创建一个文档,标题是 xxx |
| 更新文档 | @bot 在飞书文档 doc_xxx 里追加一段内容 |
| 搜索文档 | @bot 搜索飞书里标题包含 xxx 的文档 |
| 操作 | 示例命令/指令 |
|---|---|
| 创建记录 | @bot 在 Base xxx 的表 yyy 里添加一条记录 |
| 查询记录 | @bot 列出 Base xxx 中状态为待办的所有记录 |
| 更新记录 | @bot 把记录 zzz 的状态改成已完成 |
| 操作 | 示例命令/指令 |
|---|---|
| 创建日程 | @bot 帮我创建一个明天下午的会议 |
| 查看日程 | @bot 查看我今天的日程 |
| 创建任务 | @bot 创建一个任务:周五前提交报告 |
适合:发消息、查日程、改 Base 记录
[你] -> Telegram message
↓
OpenClaw main agent
↓
lark-cli --as bot
↓
飞书 API适合:写代码、debug、跑测试
[你] -> /acp spawn claude --bind here
↓
Claude Code CLI
↓
本地代码仓库适合:Claude 生成内容 -> OpenClaw 写入飞书
[你] -> /acp spawn claude --bind here
↓
Claude 生成报告 / 分析数据 / 写脚本
↓
[你@OpenClaw] 把结果发到飞书
↓
OpenClaw main agent -> lark-cli bot -> 飞书/acp spawn claude --bind here
/acp spawn claude --mode persistent --thread auto
/acp spawn claude --mode oneshot/acp status
/acp cancel
/acp close
/acp doctorlark-cli im +chat-search --query 关键词 --as bot
lark-cli im +messages-send --chat-id [已脱敏] --content "hello"
lark-cli docs +search --query 关键词 --as bot
lark-cli base +list-bases --as bot
lark-cli calendar +agenda --as bot
lark-cli task +get-my-tasks --as bot/acp spawn claude --thread auto 在 Web 控制台里会失败。| 检查项 | 状态 |
|---|---|
| OpenClaw Gateway | 运行中 (127.0.0.1:18789) |
| Telegram 渠道 | 已连接 (@duoer02_bot) |
| Feishu 渠道 | 已连接 (Clawdbot) |
| Claude Code CLI | 可用 (v2.1.79) |
| acpx -> Claude Code | 已验证通 |
| OpenClaw ACP -> Claude | 已验证通 |
| lark-cli bot 身份 | 已验证通 |
更新时间:2026-06-01
| 字段 | 内容 |
|---|---|
| 当前阶段 | 方向探索 |
| 话题发起人 | TranFu 团队 |
| 当前推进人 | TranFu 团队 |
| 最近更新时间 | 2026-06-01 |
| 当前判断 | 这个方向有交互形态想象力,但“通用 AI Notion”过宽,且存在 thin UI 与平台替代风险。更适合收敛到一个高频工作流,例如会议纪要、团队进展、投资资讯或个人信息看板,验证卡片是否真正提升信息处理效率。 |
| 下一步 | 选择一个具体场景做 3-5 张可运行卡片样例,验证用户是否愿意持续使用,而不只是觉得界面新颖。 |
AI 卡片式工作台 / AI Notion 的核心设想是:用“AI 输入框 + 可编程卡片 + AI 生成 HTML 模板 + 定时或 Hook 数据更新”构建通用型信息处理软件。用户可以通过对话创建股票、资讯、会议纪要、团队进展等卡片,卡片的数据来源可以是用户提示词,也可以是 AI 定时执行代码后的结果。
该方向的吸引力在于新的交互范式:AI 不只生成文本,而是生成可视化、可更新、可组合的信息单元。但当前最大问题是范围过大,容易变成“漂亮 UI 层”,被 Notion、飞书、ChatGPT、Claude Artifacts 或浏览器 Agent 吸收。
高频处理动态信息的个人:投资、资讯、研究、创作者。
需要看团队状态和项目进展的小团队。
希望把 AI 输出沉淀成可持续更新界面的知识工作者。
AI 对话输出容易散落,缺少持续更新的结构化界面。
Notion/飞书等工具可定制,但配置成本高,普通用户难以做动态卡片。
团队信息、会议纪要、资讯流等内容需要被压缩成可扫读、可追踪的状态块。
Lark 话题已有 16 条消息、13 条人类消息、3 个资源。
话题中已出现卡片、AI 输入框、HTML 模板、定时执行代码、会议纪要文件树、团队进展卡片、股票资讯卡片等产品元素。
已有外部参考资源,包括 kepo.ai 与 Lark 白板/文档链接。
不要先做通用平台,先选择一个场景。
做 3-5 张真实可用卡片,例如“每日投资信息卡”“项目进展卡”“会议纪要索引卡”。
验证用户是否连续 7 天打开、编辑、订阅或分享这些卡片。
验证 AI 生成卡片是否比人工配置 Notion/飞书明显省时间。
如果用户只觉得形式新颖,但不会持续打开,说明不是强需求。
如果现有 Notion/飞书/ChatGPT 已能完成核心流程,独立产品价值不足。
如果卡片生成不稳定,维护成本会高于收益。
| 字段 | 内容 |
|---|---|
| 数据口径 | 16 条消息 / 13 条人类消息 / 3 条 AI 分析 / 3 个资源。 |
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
做一个“AI 输入框 + 可组合卡片”的个人/团队信息工作台,让用户用自然语言生成、更新和调度信息卡片,把分散的资讯、会议、项目、数据和提醒变成可操作的动态页面。
小团队负责人、产品经理、投资/研究人员、运营负责人。
日常需要处理多来源信息:聊天、会议纪要、网页、任务、市场数据、项目进展。
已经使用 Notion、飞书、多维表格、Slack/飞书群、Tana/Heptabase/Obsidian,但信息仍然分散的人。
Notion/飞书等通用工作台强在结构化,但用户仍需手动建库、维护字段、同步信息。
聊天式 AI 强在生成,但结果难以长期沉淀成可复用视图。
项目/研究/运营信息不是一篇文档,而是一组不断变化的状态卡片。
用户想要“我说一句话,系统自动生成卡片、更新卡片、提醒我下一步”。
内部话题数据
话题负责人:内部成员。
消息/资源:16 / 3。
最近内部摘要:项目定位为“AI Native 信息处理软件”,用“卡片 + AI 输入框”创建和展示股票、资讯、会议纪要、团队进展等信息;数据来源既可以是用户提示词,也可以是 AI 定时执行代办。
维护报告提示:当前只拿到本地沉淀/日报/评估记录,未拿到完整逐条聊天原文,需要 best-effort。
外部资料与趋势
Notion AI 官网定位为“Search, generate, analyze, and chat—right inside Notion”,说明 AI 工作台正在从文档生成走向工作空间级搜索、分析和对话。
ClickUp Brain² 官网定位为“One AI to Replace them All”,强调工作上下文聚合和跨任务 AI。
市场趋势是“AI 嵌入现有工作台”与“Agent 执行任务”并行,纯新工作台必须有强差异化:更低建模成本、更强动态卡片、更适合移动端/群聊入口。
工作空间:Notion AI、Coda AI、Airtable AI、飞书多维表格/飞书妙记/知识库。
项目管理 AI:ClickUp Brain、Asana AI、Monday AI。
知识管理:Tana、Mem、Reflect、Heptabase、Obsidian + 插件。
AI 搜索/研究:Perplexity Spaces、Genspark、You.com、Kimi/豆包资料整理。
内部替代:直接用飞书 Base + Wiki + 内部助手 bot 做项目雷达。
推荐切“项目/机会雷达卡片工作台”,先服务现有 内部机会库 场景:
用户在群里发一个想法,AI 自动生成项目卡片。
卡片包含:一句话机会、状态、评估、证据、下一步、风险、来源链接。
卡片可被自然语言更新:“把这个项目改成 内部排序”“补一个竞品”“今天有什么新信号”。
先不做完整 Notion,做“动态项目卡片 + 每日更新 + 评估流转”。
用现有 内部机会库 做 dogfood,替代当前人工维护项目档案的部分流程。
指标:创建卡片耗时、项目状态更新准确率、团队查看/引用次数、每周被动维护减少时间。
找 3 个外部小团队试用:投资研究、产品工作室、内容团队。
观察用户是否愿意把真实项目数据放入卡片,而不是只当 demo 玩具。
与 Notion/飞书/ClickUp 正面竞争,独立产品壁垒不足。
“卡片”是交互形态,不是需求本身;如果没有明确任务流,容易变成视觉包装。
数据接入和权限管理复杂,MVP 不能一开始就追求全连接。
若用户最终仍回到 Notion/飞书,只把产品当生成器,则应转向插件/工作流,而不是独立工作台。
进入 评估中 的正式评估,但评估对象应是“内部机会库 项目卡片工作台”,不是泛 AI Notion。
画 5 张核心卡片模板:项目档案、信号、竞品、实验、日报。
用本 workspace 的项目档案维护流程做第一个 MVP 数据源。
Notion AI:https://www.notion.com/product/ai
ClickUp Brain²:https://clickup.com/ai
Airtable AI:https://www.airtable.com/platform/ai
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
这个项目需要重构叙事。若叫“AI Notion”,会天然进入 Notion、飞书、ClickUp、Airtable 的正面战场,风险很高。更合理的判断是:卡片不是产品本身,卡片必须绑定具体任务流。
当前最好的 MVP 不是泛工作台,而是复用团队内部已有 内部机会库 场景,做 项目/机会雷达卡片工作台:让群聊中的想法自动沉淀成项目卡片,持续更新证据、评估、风险和下一步。
当前状态应保持为:内部排序,重构方向 / 评估中;先评估“项目卡片工作台”,不要评估“泛 AI Notion”。
项目名:AI 卡片式工作台 / AI Notion
Lark thread:[已脱敏]
更新策略:medium
负责人:内部成员
数据来源:snapshot
消息 / 资源:16 条消息 / 3 个资源
最近话题脉络:用户要求内部助手检查本话题讨论并总结分析;内部助手说明当前只拿到本地沉淀/日报/评估记录,未拿到完整逐条聊天原文,best-effort 总结为“AI Native 信息处理软件”:用卡片 + AI 输入框创建股票、资讯、会议纪要、团队进展等信息;数据来源可来自用户提示词或 AI 定时执行代办。
证据等级:L2(有内部连续讨论和概念沉淀,但原始逐条证据不完整,尚未有外部用户/付费验证)
Notion AI:强在文档、数据库、知识库和 AI 搜索/生成;用户心智强,是最大正面竞品。
Coda AI / Airtable AI:强在结构化数据、自动化和团队工作流。
飞书多维表格 / Wiki / 妙记:对国内团队是天然替代,尤其已经在飞书内办公的组织。
ClickUp Brain / Asana AI / Monday AI:项目管理上下文强,AI 能围绕任务、文档、进展工作。
Tana / Mem / Reflect / Heptabase / Obsidian 插件:知识管理和个人信息结构化替代。
Perplexity Spaces / Genspark / Kimi / 豆包资料整理:研究、搜索、资料问答替代。
内部替代:当前 内部机会库 已经由 Lark 群 + 内部助手 bot + Wiki + Base + 项目档案维护脚本组合实现。新产品必须证明比这套拼装流程更省维护、更易查看。
MVP:内部机会库 项目卡片工作台。
围绕一个具体任务:从群聊机会到项目卡片,再到状态更新和下一步行动。
首版卡片类型只做 5 种:
项目档案卡:一句话机会、状态、负责人、优先级、评估。
信号卡:内部消息、外部资源、用户反馈、竞品变化。
竞品卡:竞品名称、定位、差异点、来源链接。
实验卡:7/14 天验证计划、指标、结果。
日报卡:今日新增、状态变化、阻塞、建议。
交互:用户在群里说“把这个想法建卡”“补一个竞品”“今天有什么新信号”“把它改成 内部排序 待验证”,系统更新卡片并保留来源。
不做泛 Notion 替代品。
不做完整数据库搭建器。
不做全类型卡片市场。
不接所有外部数据源;首版只接当前 workspace / Lark 话题 / 本地报告。
不做复杂权限体系;先在内部 dogfood。
不做移动端精美 UI 优先,先验证卡片是否减少维护成本。
不让“卡片视觉”掩盖任务流;每张卡必须能回答“谁下一步做什么”。
Day 1:画出 5 张核心卡片模板:项目档案、信号、竞品、实验、日报。
Day 2:选 4 个现有项目作为样例:GEO/AEO、AI 招聘工具、交互式知识书、AI 卡片工作台自身。
Day 3:用本地 Markdown/JSON 生成静态卡片页面或报告,不做完整前端。
Day 4:让团队用自然语言提出 10 条更新指令,例如“补竞品”“改状态”“生成 7 天计划”。
Day 5:测试系统是否能正确定位卡片、保留来源、更新字段。
Day 6:对比当前人工维护项目档案流程,记录建卡和更新耗时。
Day 7:团队评审:是否比 Wiki 长文更适合日常项目查看。
7 天通过门槛:建一张项目卡耗时减少 ≥ 50%;10 条更新指令中 ≥ 8 条能正确落到对应卡片;团队至少 2 人认为它比当前 Wiki/报告更适合日常跟进。
Week 2 前 3 天:接入每日项目维护 dry-run 输出,把状态、消息/资源数、门禁、最新摘要自动转成卡片。
Week 2 第 4-5 天:让团队连续 3 天用卡片看项目进展,而不是只看长文报告。
Week 2 第 6 天:邀请 1-2 个外部小团队看 demo,尤其是投资研究、产品工作室、内容团队。
Week 2 第 7 天:判断产品形态:独立工作台、飞书插件、还是 内部机会库 内部能力。
14 天通过门槛:内部团队真实引用卡片做决策;项目维护时间明显下降;外部团队能理解“群聊想法 → 动态卡片”的价值,而不是只觉得 UI 好看。
如果用户说“这就是 Notion/飞书多维表格换皮”,说明差异化不足。
如果卡片只能展示信息,不能推动更新和下一步行动,就只是可视化包装。
如果自然语言更新经常改错项目或丢失来源,用户会回到人工维护。
如果内部 内部机会库 都无法形成高频使用,外部商业化更不应推进。
如果真正价值来自内部助手 bot 的分析能力,而不是卡片工作台,应把它做成 bot + Wiki/Base 的增强模块,不做独立产品。
将评估对象改名为“内部机会库 项目卡片工作台”。
先用本地报告生成 5 类卡片,不做外部写入。
用 4 个现有项目 dogfood,测建卡和更新耗时。
14 天后决定:独立产品、飞书插件、还是内部运营系统能力。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
本档案是项目主页,不复制每日讨论原文。
负责人默认取 Lark 话题 root message sender。
只在场景收敛、样例推进、用户反馈、竞品资料或评估变化时更新。
更新时间:2026-06-01
| 字段 | 内容 |
|---|---|
| 当前阶段 | 机会池 / 今日新增 |
| 话题发起人 | TranFu 团队 |
| 当前推进人 | TranFu 团队 |
| 最近更新时间 | 2026-06-01 |
| 当前判断 | 这是一个把“产品想法 → 需求澄清 → 市场/用户/竞品/趋势分析 → 产品运营动作”串成 AI 工作流的平台方向。方向有需求,但容易泛化成“AI 产品经理套壳”,需要先收敛到创业者/内部创新团队的早期产品定义场景。 |
| 下一步 | 先做一个 30 分钟 MVP:输入想法后,AI 追问 5 个边界问题,并输出一页 PRD 草案、目标用户、竞品列表和验证任务。 |
2026-06-01:从当天 Lark 话题新鲜数据中识别为未映射项目话题,已补建项目档案并纳入维护流程。
2026-06-01:2026-06-01:完成自动新建/更新流程首轮演练;确认该项目已纳入 13 个有效话题口径,Wiki/Base/mapping 均已打通,后续进入轻量评估与结构补全。
这是一个把“产品想法 → 需求澄清 → 市场/用户/竞品/趋势分析 → 产品运营动作”串成 AI 工作流的平台方向。方向有需求,但容易泛化成“AI 产品经理套壳”,需要先收敛到创业者/内部创新团队的早期产品定义场景。
原始话题内容:AI 产品经理平台,用户只需要输入想法,网页上会帮它通过简短的提问明确需求和边界,然后分阶段输出市场分析、目标受众、竞争格局、行业趋势。第一版可以大概做这些,后面可以接管产品运营全流程。上线之后用户行为分析、用户画像绘制等等
待补:需通过后续讨论确认具体目标用户和购买/使用场景。
待补:当前只有初始机会描述,尚需提炼强痛点、现有替代方案和高频工作流。
2026-06-01 当天 Lark topic 原始发起消息。
话题发起人:内部成员([已脱敏])。
当前暂无外部资源和连续讨论,属于轻量机会池档案。
当前暂列 内部排序,待正式评估。评估前需要补充需求强度、AI 工作流适配、技术可行性、验证成本、分发路径和风险反证。
先做一个 30 分钟 MVP:输入想法后,AI 追问 5 个边界问题,并输出一页 PRD 草案、目标用户、竞品列表和验证任务。
如果无法收敛到明确用户和高频场景,容易变成泛 AI 工具。
如果没有可验证输出样例和真实用户反馈,不应升级为正式立项。
后续需补充外部竞品和替代方案。
| 字段 | 内容 |
|---|---|
| 数据口径 | 来自 2026-06-01 当天 Lark topic fresh fetch。 |
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
把"产品想法 → 需求澄清 → 市场/用户/竞品/趋势分析 → 产品运营动作"串成 AI 工作流的平台,优先收敛到创业者/内部创新团队的早期产品定义场景——输入一句话想法,AI 追问边界后输出一页 PRD 草案、目标用户和验证任务。
| 优先级 | 用户 | 痛点 |
|--------|------|------|
| 内部排序 | 创业者 / 独立开发者 | 有想法但不确定怎么做产品定义,缺市场分析和竞品研究能力 |
| 内部排序 | 公司内部创新团队 | 快速验证新想法,AI 辅助输出 PRD 草稿和验证任务 |
| 内部排序 | 初级/转型产品经理 | 学习产品定义方法论,用 AI 模板启动产品文档 |
| 内部排序 | 已有 PM 但需求积压的团队 | 加速想法→PRD→验证的流转,减少分析师耗时 |
从想法到 PRD 门槛高:很多好想法缺结构化的产品定义流程
市场/竞品分析重复且耗时长:每个新想法都要重新做
产品定义不严谨导致方向偏差:缺少"边界追问"来验证假设
验证任务不清晰:PRD 写完后不知道下一步该验证什么
运营阶段的工作流分散:用户分析、画像绘制、行为分析需要多个工具切换
消息/资源:原始发起消息,暂未形成连续讨论
话题发起人:内部成员
原始需求摘录:
"AI 产品经理平台,用户只需要输入想法,网页上会帮它通过简短的提问明确需求和边界,然后分阶段输出市场分析、目标受众、竞争格局、行业趋势。第一版可以大概做这些,后面可以接管产品运营全流程。上线之后用户行为分析、用户画像绘制等等。"
话题证据等级:L1(单条原始 idea,无外部资源,无连续讨论)
项目评估:待正式评估(暂列 内部排序)
当前状态:机会池 / 今日新增
市场上已有"AI PRD 生成"类工具(如 Vondy、Figma AI、Productboard AI 等),但多为单项功能而非全流程平台
创业者/独立开发者的"想法→产品"问题是 AI 应用层共识方向(Y Combinator、ProductHunt 热门标签)
竞品多为单点工具:AI 需求分析(craft.io)、AI 竞品分析(Exploding Topics、Similarweb AI)、AI 用户画像
"完整产品运营全流程"的产品形态在市场上尚无明确赢家,说明有机会但需要高度收敛
内部已有相关沉淀:Product Demand Automation 项目(群聊需求自动识别/沉淀)、AI Interview 项目(求职者面试辅助)
| 类型 | 代表 | 特点 |
|------|------|------|
| AI PRD 生成 | Vondy AI、Figma AI、Productboard AI | 单点功能,非全流程 |
| AI 竞品/市场分析 | Exploding Topics、Similarweb AI、G2 | 分析报告为主,不连接产品定义流程 |
| AI 产品需求管理 | Notion AI、Linear AI、Craft AI | 偏向协同和文档,非产品定义引擎 |
| 全流程产品平台 | 目前无明显赢家 | 机会最大,但产品复杂度最高 |
不做完整全流程平台;先做"想法→PRD 草稿"单点验证。
MVP 功能(可 30 分钟内完成):
输入:用户一句话产品想法(如 "一个帮小团队管理 AI API Key 的工具")
AI 追问:自动追问 5 个边界问题(目标用户、核心场景、地域/语言、商业模式、验证方式)
输出:
PRD 草案(一页纸)
目标用户描述
竞品列表(Top 3-5)
定义验证任务清单(按优先级排列)
交付形态:
第一期可通过 concierge 或简单 Chat UI 完成
不需要复杂 SaaS 或 Workflow 引擎
用户反馈后调整追问模板和输出结构
找 3-5 位目标用户(创业者、公司内创新团队、初级 PM)
让每人输入一个真实想法,观察:
AI 追问是否帮他们发现了之前没考虑的问题
PRD 草案质量是否达到可讨论/可评审的程度
是否比"自己写/用 Notion/用 ChatGPT"更好
用户愿意继续用 ≥ 60%
用户愿意把输出给团队讨论 ≥ 50%
"我学到了新东西"反馈率 ≥ 40%
| 风险 | 可能性 | 影响 | 缓解 |
|------|--------|------|------|
| 泛化成"AI PM 套壳" | 高 | 致命 | 严格收敛到"想法→PRD 草稿"单点 |
| 竞品快速出现(ChatGPT 等通用 AI 已能回答类似问题) | 高 | 严重 | 差异化不是生成内容,而是追问边界+结构化输出+验证任务 |
| 输出质量不稳定导致用户不信任 | 中 | 中 | 固定模板 + 人工校对 |
| 用户痛点不够强:有多少人"想做产品定义但缺方法" | 中 | 中 | 通过用户访谈验证 |
| 同类话题内部沟通未形成连续讨论 | 中低 | 中 | 需要推动话题讨论 |
我会改变看法的触发条件:
5 位用户测试后无人认为比"用 ChatGPT 写 PRD"更好
追问模板对大部分想法没有新增价值
内部话题讨论中断,无推进人
第 1 步(30 分钟):搭建追问+PRD 草稿输出 MVP 原型 第 2 步(7 天):找 3-5 位目标用户做 concierge test 第 3 步(通过后):固定追问模板和输出格式,制作简单 landing page 第 4 步(中期):考虑是否集成市场分析/竞品分析/用户行为分析模块
不建议的路线:一开始做完整全流程产品运营平台 / 用户行为分析 / AI 画像绘制 = 过早泛化
内部产品需求自动化项目:docs/memory/projects/product-demand-automation/
内部 AI 面试产品项目:docs/memory/projects/ai-interview/
ProductHunt / Y Combinator 共识:AI 应用层"想法→产品"方向
竞品参考:Vondy AI、Productboard AI、Craft AI、Notion AI
行业报告:Gartner "AI in Product Management" (2025) — 待补充公开来源
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
标题:AI 产品经理平台
Doc / Wiki:S8uPd237voLE3QxAP5clDlk3g6c / AcC8w8p0fiOdQqkLoMFlVW4KgBg
话题负责人:内部成员
内部数据:2026-06-03 维护报告中该项目来自 mapping,topic_messages 为 0;档案 plain 文本保留原始话题:用户输入想法,网页通过简短提问明确需求和边界,然后分阶段输出市场分析、目标受众、竞争格局、行业趋势,后续可接管产品运营、用户行为分析、画像绘制等。
方向成立,但最大风险是过宽:如果从一开始就说“AI 产品经理平台”,很容易滑向模板化 PRD 生成器、市场分析生成器、Notion AI 页面或通用 Agent 套壳。
更好的切法是:服务早期产品机会验证,把模糊想法压缩成可执行的 MVP 假设、验证计划和下一步任务。它不应该替代完整产品经理,而是帮助创业者/小团队把“我有个想法”推进到“本周可以验证什么”。
当前建议保持 内部排序,先做“30 分钟产品定义工作流”。
独立开发者 / AI 小工具创业者:点子多、开发快,但需求边界、用户定义、验证任务混乱。
2-10 人早期团队:没有专职产品经理,需要把想法整理成可开发、可验证的任务。
内部创新 / 机会雷达团队:需要把机会话题转成项目档案、评估、MVP、验证记录。
Agency / 产品顾问:需要更快地产出需求澄清、竞品初筛和方案草案。
痛点:
想法容易停留在一句话,没有目标用户、痛点、替代方案、验证指标。
ChatGPT 能生成 PRD,但经常不追问关键边界,输出“看起来完整但不可执行”。
市场分析、竞品、用户画像、MVP、埋点、反馈复盘分散在不同工具。
产品上线后,AI 代码工具不知道此前的商业假设和用户反馈。
ChatGPT / Claude / Gemini:最强通用替代;弱点是缺固定工作流、项目记忆和验证闭环。
Notion AI / Coda AI / 飞书妙记/多维表格 AI:适合文档协作和知识整理;不专门围绕产品机会推进。
Productboard / Aha! / Jira Product Discovery / Linear:成熟需求和路线图工具;更偏已有产品团队,不解决“从想法到验证”的早期混沌。
Miro / FigJam / Whimsical:适合头脑风暴和流程图;AI 只能辅助,不承担验证推进。
各类 PRD 生成器:输出快,但往往模板化、缺真实用户和后续执行。
推荐 MVP:产品想法澄清器 + 验证任务生成器。
输入:一句产品想法。
流程:AI 只追问 5 个关键问题:
谁最痛?
现在怎么解决?
为什么现在会换?
第一版只做哪一个场景?
用什么证据判断继续/停止?
输出:
一页机会卡:用户、痛点、替代、MVP、验证指标、风险反证。
7 天验证计划。
5 个访谈问题。
3 个竞品/替代方向。
可导出到文档或看板的任务清单。
不做:
不做完整 PM SaaS。
不做研发项目管理、排期、绩效。
不自动生成长 PRD。
不声称能接管产品运营全流程。
不做泛市场报告生成。
选 10 个真实机会话题,使用该流程生成机会卡。
让 3 类用户评估:独立开发者、早期团队负责人、产品经理。
和“直接问 ChatGPT 生成 PRD”对比,看哪一个更能推动下一步行动。
核心指标:
用户是否认为输出减少了澄清时间。
是否愿意按输出执行 7 天验证。
生成内容中多少需要人工重写。
是否愿意每月为机会库/验证闭环付费。
用户直接用 ChatGPT prompt 就够了,不需要单独产品。
输出太像模板,不能处理复杂上下文。
目标用户不一致:创业者要快,产品经理要深,Agency 要可交付物。
竞品和市场分析如果不能引用来源,会被认为不可信。
用户真正痛点在获客和开发,不在产品定义。
把当前 内部机会库 的项目档案结构抽象成第一个 demo。
用 5 个内部机会跑一遍,记录人工修改点。
先做网页表单 + Markdown 输出,不做账号系统。
如果内部连续使用 2 周仍有价值,再考虑外部访谈。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
本档案由当天新鲜话题数据触发创建,避免旧 snapshot 漏项。
后续项目档案维护必须先拉取当天 Lark 数据,再对比 mapping/Base/Wiki。
更新时间:2026年05月22日 16:45(北京时间)
| 字段 | 内容 |
|---|---|
| 当前阶段 | 方向探索 |
| 话题发起人 | TranFu 团队 |
| 当前推进人 | TranFu 团队 |
| 最近更新时间 | 2026-06-01 |
| 当前判断 | AI生活助手方向过宽,现阶段不能当作已验证项目推进。它更适合作为需求收集池,先从家庭事务、老人提醒陪伴、健康饮食执行等垂直生活场景里筛选一个高频刚需切口。 |
| 下一步 | 先收集 3-5 个真实生活场景样本,记录用户、频率、现有替代方案、AI 可节省的时间/焦虑和付费可能性;样本不足前不进入产品验证。 |
2026-06-01:完成观察型项目档案结构化试点。当前保留原正文“证据弱、方向宽、需重构”的判断,只新增项目状态卡、最新进展、数据链接和维护说明;该项目后续不做高频维护,只在出现真实场景样本时更新。
2026-05-22:Lark 话题创建,原始需求为“AI生活助手,AI帮你解决日常生活的问题”。目前只有 1 条人类消息、0 个外部资源,证据等级较低。
AI生活助手不是一个可以直接立项的“泛助手”项目,而是一个需要从 Lark 话题中继续收集真实生活场景、再筛选垂直切口的早期机会。
当前 Lark 核心证据很弱:只有 1 条用户根消息,主题是“AI生活助手 AI帮你解决日常生活的问题”,缺少具体场景、用户画像、频率、现有替代方案、付费意愿和后续讨论。因此本报告不能把它判断为已验证需求,只能判断为 值得观察和结构化收集需求的方向。
外部市场证据显示,AI personal assistant / intelligent virtual assistant / AI companion / family AI assistant / elderly care AI / AI health coach 等方向都在增长,且大厂和创业公司都在布局。但这也意味着泛化竞争极强。第三项目最优策略不是做“万能生活助手”,而是通过 7-14 天验证,从 3 个垂直场景中选一个:
家庭事务协调助手 老人提醒与陪伴助手 健康饮食执行助手
| 字段 | 内容 |
|---|---|
| 话题群 | Tranfu AI机会 |
| 项目标题 | AI生活助手AI帮你解决日常生活的问题 |
| 当前阶段 | new |
| 已有信号 | 1 条消息 / 用户 1 条 / AI 分析 0 条 / 资源 0 个 |
| 项目档案 | [内部链接已脱敏] |
【事实】Lark 话题中目前只有一个非常宽泛的项目根消息:
AI生活助手,AI帮你解决日常生活的问题。
【事实】目前没有多轮群内讨论,也没有形成具体共识。
【事实】目前没有可记录分歧。
【事实】资源数为 0,暂无链接、附件、竞品、截图或用户案例。
【推断】从内部前台总览和已有项目卡片看,团队已初步判断:
AI生活助手方向太宽,需要先收集 3-5 个高频生活场景,再筛选切入点。
具体用户是谁:家庭主理人、老人子女、高压职场人、育儿家庭,还是普通消费者?
高频场景是什么:家庭任务、饮食健康、老人照护、消费决策、日程管理?
用户现在怎么解决:微信、备忘录、日历、外卖/买菜 App、智能音箱、家庭群?
AI 能不能明显节省时间或降低焦虑?
用户是否愿意付费,还是只把它当免费大模型功能?
Lark 证据:L1/L2 边界
原因:有真实话题根消息,但缺少多轮讨论、样本、行为信号或付费/负责人证据。
本报告按 elite-market-project-research 执行:
Lark Topic Evidence Core:以 Lark 话题为核心证据,明确当前内部证据不足;
Elite Market Researcher:做第一性原理、拐点、反共识、事前验尸;
Market Analysis:补充外部市场、竞品、用户痛点和政策风险;
Project Scoring:按 10 维度评估,并结合 Lark 证据等级降级。
AI生活助手项目档案;
机会雷达前台总览;
Lark Topic Project Phase 1 Verification;
Lark topic ingestion fix 文档;
话题项目 workflow 文档。
本次使用 Brave Search 补充检索,覆盖:
AI personal assistant market;
intelligent virtual assistant market;
consumer AI assistant products;
AI companion apps;
family AI assistant / household management;
AI health coach / personalized nutrition;
AI elderly care assistant;
AI agent startup funding。
“AI生活助手”这个词本身没有商业含义。它必须还原成一个更具体的问题:
谁,在什么生活场景里,反复遇到什么麻烦; 这个麻烦现在怎么解决; AI 能不能以更低成本、更低心智负担、更高可靠性解决; 用户是否愿意为这个结果付费或持续使用。
日常生活问题有三个特点:
高频但碎片化:买菜、做饭、日程、家庭沟通、健康、育儿、老人照护都很高频,但彼此差异大;
强上下文依赖:生活助手必须知道家庭成员、习惯、预算、健康状况、日程和偏好;
信任门槛高:健康、老人、孩子、财务、隐私都不是简单聊天能解决的。
所以泛化 AI 生活助手的问题是:
场景太多 → 数据太杂 → 价值不清 → 用户不付费 → 被 ChatGPT/Siri/Gemini/Alexa 替代。
更好的路径是:
先找一个高频、强痛、低风险、可验证的生活场景。
AI生活助手可以拆成 6 个子赛道:
| 子赛道 | 代表方向 | 机会判断 |
|---|---|---|
| 通用个人助手 | ChatGPT、Gemini、Copilot、Siri、Alexa | 大厂入口,创业难度高 |
| 家庭事务助手 | 日程、任务、饭菜、购物、家务协同 | 有垂直机会,适合验证 |
| 老人照护助手 | 陪伴、提醒、健康打卡、异常通知 | 痛点强,但责任风险高 |
| 健康饮食助手 | 饮食计划、运动、营养、体重管理 | 需求大,但合规和信任要求高 |
| AI Companion | 陪伴、情绪、聊天、角色互动 | C 端已有收入,但风险和同质化高 |
| 消费决策助手 | 买什么、怎么选、比价、避坑 | 容易做 demo,但留存和商业模式需验证 |
【事实】外部资料显示,AI Assistant / Intelligent Virtual Assistant 市场在 2025-2032/2035 年有高增长预期,不同报告给出 20%+ 到 40%+ 的 CAGR。ChatGPT、Gemini、Copilot、Siri、Alexa 等正在成为个人任务、问答、日程、搜索、内容生成入口。
【推断】这说明用户接受 AI 助手的教育成本在下降,但也意味着泛助手入口已经被大厂占据。
趋势:上升。强度:高。
【事实】外部资料和产品复盘中,Rabbit R1、Humane AI Pin 等硬件型 AI 助手受挫,而 Limitless、家庭管理、AI companion、AI health coach 等更垂直的场景仍在探索。
【推断】用户不是不需要 AI 助手,而是不需要一个没有明确场景的“AI 盒子”。
趋势:从泛硬件转向软件和垂直场景。强度:中高。
【事实】TechCrunch 等资料显示,AI companion apps 在 2025 年移动端收入可达约 1.2 亿美元量级,Replika、Character.AI、Chai 等产品有明确用户群。
【推断】C 端确实会为 AI 互动付费,但陪伴/情绪价值与“帮我解决生活问题”的执行价值不同,不能直接等同。
趋势:上升。强度:中。
【事实】Brave 检索中出现 Nori、familymind、Honeydew 等家庭 AI assistant,聚焦 shared calendar、tasks、meal planning、chores、shopping lists 等家庭协同任务。
【推断】家庭事务协调可能比泛个人助手更适合创业切入,因为它有明确的多人协作、重复任务和碎片信息整合需求。
趋势:早期上升。强度:中。
| 用户 | 高频痛点 | 是否适合第一阶段 |
|---|---|---|
| 家庭主理人 / 父母 | 日程、购物、吃饭、孩子活动、家务分配 | 高 |
| 成年子女 / 老人照护者 | 提醒吃药、健康打卡、陪伴、异常通知 | 中高,但风险高 |
| 高压职场人 | 日程、任务、饮食、运动、自我管理 | 中 |
| 育儿家庭 | 教育安排、活动、作业、沟通、资料整理 | 中高 |
| 普通消费者 | 买东西、选服务、比价、避坑 | 中 |
| 银发用户本人 | 陪伴、提醒、语音交互 | 中,但交互和硬件门槛高 |
用户不会为“AI生活助手”付费,但可能为这些结果付费:
家里少吵架、少漏事;
老人按时吃药、子女放心;
每周买菜做饭更省心;
育儿信息和活动安排不混乱;
健康饮食有持续执行;
复杂消费决策少踩坑。
代表:ChatGPT、Gemini、Claude、Copilot、Siri、Google Assistant、Alexa。
优势:
用户入口强;
模型能力强;
与系统、搜索、日历、邮件、智能家居整合;
泛问答成本低。
弱点:
不一定懂家庭长期上下文;
不一定能稳定执行生活流程;
多人家庭协作能力仍弱;
垂直场景体验不够深。
代表:Replika、Character.AI、Chai、PolyBuzz 等。
优势:
陪伴和情绪价值明确;
C 端付费已有验证;
使用频率高。
弱点:
与生活事务执行关系弱;
伦理和心理依赖风险;
同质化强。
代表:Nori、familymind、Honeydew、Cozi、shared calendar / meal planning / chore apps。
优势:
具体场景;
高频重复;
家庭多人协作;
AI 可处理自然语言、图片、邮件、学校通知。
弱点:
家庭协作产品留存难;
需要成员共同使用;
付费意愿需验证。
代表:AI health coach、nutrition AI、ElliQ、Alexa for Seniors、Google Nest Hub 等。
优势:
痛点强;
愿付费人群更明确;
可与硬件/医疗/保险/养老渠道结合。
弱点:
隐私、健康建议、责任边界要求高;
需要可信数据和人类审核;
老年用户交互门槛高。
家庭信息碎片化:学校通知、工作日程、老人需求、购物清单散落在微信/短信/日历;
生活执行断点多:知道要做,但没人持续提醒、分配、跟进;
照护焦虑:老人、孩子、健康相关问题让家庭成员持续担心;
决策成本高:买什么、吃什么、去哪儿、怎么安排,需要反复比较;
泛助手没有上下文:ChatGPT 能回答,但不了解“我家”的真实情况。
| 机会 | 痛点强度 | AI 解决难度 | 风险 | 判断 |
|---|---|---|---|---|
| 家庭事务协调助手 | 高 | 中 | 中 | 最推荐验证 |
| 老人提醒与陪伴助手 | 高 | 中高 | 高 | 可验证,但需责任边界 |
| 健康饮食执行助手 | 中高 | 中 | 高 | 有需求,但不能做医疗建议 |
| 消费决策助手 | 中 | 低 | 低 | demo 容易,留存弱 |
| 泛个人助手 | 不确定 | 高 | 中 | 不建议切入 |
一个面向家庭主理人/父母的 AI 家庭运营助手。
输入:
家庭成员日程;
学校/兴趣班通知;
菜谱/购物需求;
家务任务;
微信/短信/邮件截图或文本。
输出:
本周家庭计划;
购物清单;
家务分配;
提醒事项;
冲突检测;
每日家庭简报。
与 Lark 原始需求“解决日常生活问题”最接近;
生活问题足够具体;
高频、重复、可验证;
不直接触碰医疗/心理/金融高风险;
可以用微信/飞书/表格/日历做轻量原型。
用户每晚发一段/几张截图:明天家庭事项。 AI 输出:明日家庭安排 + 购物/提醒/分工清单。
面向成年子女,为老人提供提醒、陪伴、健康打卡和异常通知。
核心功能:
吃药提醒;
喝水/运动提醒;
每日问候;
情绪/异常状态提示;
子女简报。
痛点强;
付费方明确:成年子女;
有社会价值。
健康和安全责任高;
老人使用门槛;
需要硬件/语音/微信生态;
不能替代医疗或护理。
面向想减脂、控糖、改善饮食的人,帮助做菜谱、购物、打卡和执行。
核心功能:
每周饮食计划;
购物清单;
外卖选择建议;
饮食记录;
运动提醒;
执行复盘。
高频;
可与已有健康数据结合;
目标结果明确。
健康建议合规风险;
需要数据准确;
用户容易三分钟热度。
适合家庭事务和健康饮食助手。
价格假设:
¥19 - ¥49 / 月
但必须证明高频留存,否则订阅难成立。
适合老人照护和健康助手。
渠道:
养老机构;
社区服务;
保险公司;
健康管理机构;
企业员工福利。
早期最适合:
7 天家庭生活助理试用
先人工 + AI 交付,不急着做 App。
反共识判断:市场大不代表项目好,泛生活助手是最危险的切法。
因为通用助手已经被 ChatGPT、Gemini、Siri、Alexa 等占据。创业团队做泛助手,会被入口、模型、系统权限和数据上下文同时压制。
置信度:高。
反共识判断:陪伴付费成立,但生活助手不一定要做陪伴。
家庭任务、老人照护、饮食执行需要的是可靠、可控、可审计的执行辅助,不是拟人聊天。过度拟人反而可能增加信任和责任风险。
置信度:中高。
反共识判断:第一阶段不应该做 App,而应该做微信/飞书/表格/日历上的 concierge test。
生活助手的难点不是界面,而是是否有真实高频场景和持续使用动机。
置信度:高。
项目类型:research_probe + commercial_product 早期观察。
| 证据类型 | 等级 | 说明 |
|---|---|---|
| Lark 证据 | L1/L2 边界 | 有真实话题根消息,但只有 1 条,缺少多轮讨论和样本 |
| 外部证据 | L1 | 市场和竞品资料丰富,但不能替代内部真实需求 |
| 综合证据 | L1+ | 可做研究和场景收集,不足以立项 |
| 维度 | 权重 | 分数 | 证据 | 备注 |
|---|---|---|---|---|
| Demand reality | 16 | 42 | Lark 只有 1 条宽泛需求 | 具体用户和场景不清晰 |
| AI workflow fit | 12 | 70 | 外部竞品和场景支持 | AI 适合计划、总结、提醒、推荐 |
| Technical feasibility | 10 | 72 | MVP 可用现有工具完成 | 不建议先做 App |
| Validation feasibility | 10 | 66 | 可做 7 天 concierge test | 需要找到真实家庭/用户样本 |
| Distribution reachability | 10 | 45 | 暂无明确第一批用户 | 可从团队身边家庭样本开始 |
| Business/value recovery | 10 | 45 | C 端付费待验证 | 老人/健康可能有付费方 |
| Reuse and retention | 8 | 58 | 家庭/健康场景有复用 | 泛助手留存不确定 |
| Cost structure | 8 | 68 | 模型成本低,人工服务成本可控 | 早期人工介入可接受 |
| Risk and responsibility | 8 | 48 | 老人/健康/隐私风险较高 | 必须限定非医疗/非安全决策 |
| Tranfu fit | 8 | 70 | 符合 AI Agent + 生活工作流探索 | 需收敛场景 |
状态:重构方向 / 继续收集需求 证据等级:L1+
| Gate | 结果 |
|---|---|
| User gate | 未完全通过:目标用户太泛 |
| Demand gate | 未完全通过:缺频率、损失和当前替代方案 |
| AI-fit gate | 部分通过:垂直场景 AI fit 好,泛助手 AI fit 不清晰 |
| Responsibility gate | 条件通过:必须排除医疗诊断、心理干预、安全承诺 |
不要立刻做产品;先用 Lark 话题补采 3 个真实生活场景,并选 1 个做 7 天 concierge test。
补拉 [已脱敏] 原始 thread;
在话题里追问:你希望 AI 解决哪 3 个日常生活问题?
找 5 个团队/朋友样本,收集真实生活场景。
每个样本必须记录:
用户是谁 场景是什么 频率多高 现在怎么解决 哪里痛 是否愿意试用 是否愿意付费
建议候选:
家庭事务协调;
老人提醒与陪伴;
健康饮食执行。
优先选择“家庭事务协调”:
用户每天晚上发明天家庭事项;
AI 输出明日安排、提醒、购物清单、分工建议;
第二天收集是否有用、是否减少漏事。
通过标准:
至少 3 个用户完成 5 天以上试用;
用户每天愿意主动发信息;
至少 2 个用户认为“明显省心”;
至少 1 个用户愿意继续用或付费;
没有明显隐私/责任风险。
明天/本周家庭事项;
学校/活动通知截图;
购物/做饭需求;
家庭成员时间限制;
重要提醒。
明日家庭简报;
待办清单;
购物清单;
时间冲突提醒;
家务/任务分配建议;
晚间复盘问题。
第一阶段不用 App:
Telegram / 微信 / Lark 群聊 + 表格记录 + AI 总结
不做医疗诊断;
不做安全承诺;
不处理高敏隐私;
不自动决策,只做提醒和建议;
所有家庭成员数据最小化保存。
假设 2 年后这个项目失败,最可能原因:
一开始做成泛生活助手,没有具体场景;
用户觉得 ChatGPT / Siri / Gemini 已经够用;
家庭协作需要多人使用,推广困难;
用户不愿持续输入生活数据;
隐私和信任问题阻碍留存;
健康/老人场景责任风险过高;
C 端订阅付费意愿不足。
我会改变看法的触发条件:
5 个真实样本里没有一个高频场景;
7 天 concierge test 中用户不愿持续发送生活事项;
用户认为 AI 输出和普通备忘录/日历没有区别;
用户明确不愿为省心/提醒/安排付费;
涉及隐私和责任风险无法合理控制。
AI生活助手当前不应进入正式立项。
建议状态:
重构方向 / 继续收集需求
推荐方向:
从“AI生活助手”重构为“家庭事务协调助手”做小样本验证。
唯一主线下一步:
补拉 Lark 原始话题 + 收集 5 个真实生活样本 + 选家庭事务协调做 7 天 concierge test。
如果验证通过,再升级为:
先验证 / 小步立项候选
如果验证失败,继续观察,不投入产品开发。
AI生活助手项目档案;
机会雷达前台总览;
Lark Topic Project Phase 1 Verification;
Lark topic ingestion fix 20260522;
Lark topic project workflow。
Technavio: Personal AI Assistant Market Growth Analysis 2025-2029;
Precedence Research: Intelligent Virtual Assistant Market;
Market Research Future: Intelligent Personal Assistant Market;
a16z: State of Consumer AI 2025;
TechCrunch: AI companion apps revenue trend 2025;
Nori / familymind / Honeydew family AI assistant product materials;
Mordor Intelligence / healthcare market reports on AI personalized nutrition;
AI elderly care / companion robot market materials;
Crunchbase / TechCrunch AI agent startup funding materials。
| 字段 | 内容 |
|---|---|
| 当前数据口径 | 1 条话题消息 / 1 条人类消息 / 0 条 AI 分析 / 0 个外部资源;后续需补真实生活场景样本。 |
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
把“AI生活助手”从宽泛个人助理重构为一个高频、可验证的垂直生活场景助手,例如“家庭事务/本地生活决策/个人日程与消费执行”的轻量 Agent。
一线/新一线城市中高压知识工作者、年轻家庭、独居人群。
有大量碎片化生活事务:购物、出行、缴费、预约、家庭日程、亲友提醒、账单和生活决策。
已使用 ChatGPT、豆包、Kimi、通义等通用助手,但缺少“持续记忆 + 场景执行 + 本地生活整合”的用户。
通用聊天助手能回答,但不能稳定接管生活任务闭环。
生活任务高度碎片化,用户不愿为低价值问题反复输入上下文。
真正有价值的是“记住我的偏好、预算、家庭成员、日程约束,并主动给建议/提醒/执行”。
难点在于生活助手太泛,缺少初期高频刚需切口。
内部话题数据
话题负责人:内部成员。
消息/资源:1 / 0。
最近内部摘要仅有一句:“AI生活助手 AI帮你解决日常生活的问题”。
维护报告判断:只有出现明确生活场景、用户群、使用频次或付费线索时才更新。
外部资料与趋势
大模型厂商正在把聊天机器人升级为可执行任务的助手/Agent,说明“个人助理”是长期方向,但通用入口竞争极强。
可访问资料显示,Notion AI 的定位已从写作助手扩展为“Search, generate, analyze, and chat—right inside Notion”,反映 AI 助手价值正在嵌入用户已有工作/生活信息容器,而非单独泛问答。
Perplexity、OpenAI、Google Gemini、Apple Intelligence 等均在推进个人助理、手机入口、跨应用上下文和任务执行能力,独立创业项目需要避开“泛个人助理”正面竞争。
通用 AI 助手:ChatGPT、Gemini、Claude、豆包、Kimi、通义千问。
手机系统助手:Siri/Apple Intelligence、Google Assistant/Gemini、荣耀/小米/OPPO/vivo 手机 AI 助手。
本地生活平台:美团、饿了么、携程、高德、滴滴、支付宝/微信服务入口。
垂直管理工具:日历、待办、记账、家庭共享清单、智能家居 App。
建议不要做“万能生活助手”,先选一个可复用场景:
家庭生活运营 Copilot:家庭成员日程、购物清单、缴费、维修、旅行准备、孩子事务提醒。
本地生活决策助手:基于预算/口味/距离/时间限制,帮用户筛选餐厅、亲子活动、周末安排。
个人事务 Inbox:用户把生活消息、截图、账单、提醒丢进一个入口,AI 自动分类、提醒和生成下一步。
推荐 MVP:家庭生活运营 Copilot。因为它更容易形成持续记忆与复购价值,也更适合后续和育儿/教育方向联动。
找 10 个年轻家庭或高压职场用户,收集一周生活事务清单,统计高频任务与愿意外包的任务。
用飞书/Notion/微信机器人做 Wizard-of-Oz 原型:用户转发生活信息,人工+AI 生成提醒、清单、建议。
核心指标:每周主动提交事务数、提醒采纳率、节省时间主观评估、连续使用 2 周留存、愿意支付价格。
泛生活助手容易被手机系统级 AI 和大模型 App 吞掉。
本地生活执行依赖平台 API/生态合作,创业团队很难直接闭环。
用户对隐私敏感:家庭成员、账单、位置、日程属于高敏数据。
若用户每周生活事务提交少于 3 次,说明频次不足,不适合独立产品化。
把项目状态维持为“观察 / 重构方向”,不要进入开发。
补 10 个用户访谈,优先验证“家庭生活运营”是否有高频、强记忆、愿付费。
若两周内无法找到明确高频场景,建议合并到“育儿教育类产品”或“AI 卡片式工作台”的生活卡片模块。
Notion AI 产品页:https://www.notion.com/product/ai
ClickUp Brain² 产品页:https://clickup.com/ai
Khanmigo 产品页(教育助理参考):https://www.khanmigo.ai/
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
这个项目现在不应该被理解成“做一个 AI personal assistant”。这个叙事太宽,正面撞上 ChatGPT、Gemini、豆包、Kimi、手机系统助手和本地生活超级 App。内部证据也很薄:只有一句“AI生活助手 AI帮你解决日常生活的问题”。
更合理的处理方式是:保留为 内部排序 观察 / 重构方向,等待它被一个具体生活场景重新命名。 目前最有希望的不是“回答日常问题”,而是“记住家庭上下文并持续处理小事务”:缴费、维修、购物、旅行准备、孩子事务、亲友提醒、周末安排。
如果两周内不能找到高频、强记忆、可重复提交的任务,应暂缓独立项目化,并考虑合并到 parenting_education_product 的家庭模块,或 ai_card_workspace 的个人/家庭卡片模块。
标题:AI生活助手
Lark thread:[已脱敏]
更新策略:low
负责人:内部成员
数据来源:snapshot
消息 / 资源:1 条消息 / 0 个资源
最近消息摘要:AI生活助手 AI帮你解决日常生活的问题
证据等级:L1(只有概念句,无具体用户、场景、频次、替代方案、付费线索)
通用 AI 助手:ChatGPT、Gemini、Claude、豆包、Kimi、通义。它们覆盖问答、规划、写作和轻量建议,是泛助手方向的最大替代。
手机系统助手:Siri / Apple Intelligence、Google Gemini、各国产手机 AI 助手。优势是系统权限、通知、日历、位置和跨 App 上下文。
本地生活平台:美团、高德、携程、滴滴、支付宝、微信服务。真实执行能力强,独立助手很难绕过它们闭环。
家庭/个人管理工具:日历、待办、记账、家庭共享清单、Notion/飞书/备忘录。它们不智能,但用户已有习惯。
推荐 MVP:家庭生活运营 Copilot,而不是万能生活助手。
只做:
用户把生活事务丢进一个入口:截图、语音、文字、账单、学校通知、维修事项。
AI 自动归类为:待办、提醒、购物、家庭成员事项、费用、出行、家政维修。
输出下一步:什么时候做、谁负责、需要准备什么、可选方案。
每周生成一页家庭生活复盘:未完成事项、下周提醒、可节省的钱/时间。
明确不做:
不做开放式“什么都能问”的聊天 App。
不接入支付、下单、打车、订票等高风险执行闭环。
不收集过量隐私;位置、账单、家庭成员信息必须最小化。
不做医疗、法律、投资、心理等专业建议。
不先做移动端完整 App;先用飞书/微信/Notion/Wizard-of-Oz 验证。
7 天验证:生活事务日志
找 10 个目标用户:年轻家庭、高压职场用户、独居但事务多的人。
让他们连续 7 天记录生活待办和临时事务,不要求使用产品。
统计:每人每周事务数、重复事务占比、需要记忆上下文的事务占比、愿意外包给 AI 的事务。
访谈问题:哪 3 类最烦?如果 AI 提醒/整理/给方案,愿不愿意每周用?愿不愿意付费?
14 天验证:Wizard-of-Oz 家庭 inbox
建一个单入口群/机器人,用户转发生活消息。
后台人工 + AI 生成分类、提醒和下一步建议。
核心指标:每周主动提交 ≥ 5 次的用户比例;提醒采纳率;连续 2 周留存;用户是否愿为“家庭事务整理”付费。
如果用户每周主动提交生活事务少于 3 次,频次不足,不适合独立产品。
如果用户只把它当通用问答,不愿交给它记忆家庭信息,则无法形成差异化。
如果任务最终都要跳到美团/高德/微信/支付宝手动完成,产品价值可能只是“提醒工具”。
如果用户对家庭隐私明显不放心,应降级为本地/私密模板工具。
如果育儿、家务、出行三个场景都能跑,但没有一个强,应合并到更具体项目,不保留泛生活助手。
暂不开发,先补 10 个用户的一周生活事务样本。
把候选切口限定在“家庭生活运营”“个人事务 inbox”“本地生活决策”三选一。
与 parenting_education_product 联动:如果父母端高频需求更强,就把生活助手降级为育儿家庭助手的基础设施。
两周后仍无高频场景,建议从项目看板降级为观察标签。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
本档案是观察型项目主页,不是正式验证项目;不要因为“AI生活助手”概念大就自动提高优先级。
负责人默认取 Lark 话题 root message 的 sender;本项目话题发起人为“内部成员”,Lark 原始显示名为“内部成员”。
自动维护只允许更新项目状态卡、最新进展、数据链接和维护说明;原有研究正文默认不覆盖。
只有出现明确生活场景样本、用户访谈、使用频次、付费线索或 MVP 切口时,才应更新项目判断或评估。
进入自动写入前,必须先通过 scripts/update_project_archives.py --project-id ai_life_assistant --fetch-docs 的 dry-run 门禁。
更新时间:2026年05月22日 16:55(北京时间)
| 字段 | 内容 |
|---|---|
| 当前阶段 | 验证中 |
| 话题发起人 | TranFu 团队 |
| 当前推进人 | TranFu 团队 |
| 最近更新时间 | 2026-06-01 |
| 当前判断 | GEO/AEO 已具备明确内部需求、成熟工具线索和外部趋势,适合从“AI 可见性审计报告”切入做客户验证;第一阶段不建议直接做完整 SaaS。 |
| 下一步 | 用 7-14 天为 3 个品牌做样例审计,验证客户是否愿意为 AI 答案中的品牌存在感、引用来源、竞品对比和优化建议付费。 |
2026-06-01:完成项目档案维护结构试点。当前保留原正文和研究判断,只新增项目状态卡、最新进展、数据链接和维护说明;后续每日根据 Lark 话题进展、外部信号和 Score History 增量更新。
2026-06-01:工程化维护流程验证完成。update_project_archives.py 已支持单篇受控写入,默认仍为 dry-run;write 模式必须指定 project-id,只追加“最新进展”受控区块,不开放全量写入。
GEO/AEO 是搜索入口从“网页列表”迁移到“AI 直接答案”后产生的新型品牌可见性赛道。它解决的不是传统 SEO 排名问题,而是:当用户在 ChatGPT、Perplexity、Gemini、Google AI Overviews、Claude、Copilot、豆包、DeepSeek、Kimi、元宝、文心一言、夸克 AI、通义等 AI 搜索/问答入口询问“哪个产品更好”“某公司怎么样”“某领域推荐谁”时,品牌是否出现、是否被正确描述、是否被引用、是否被推荐。
按新版 elite-market-project-research 规则,本项目以 Lark 话题数据为 内部排序 核心证据:该话题由用户明确提出,已经有 6 条话题消息、4 条人类消息、2 条 AI 分析,以及 Profound、Scrunch、AthenaHQ、Peec、Promptwatch、Otterly、Goodie、Writesonic 等 8 个去重资源。外部 Brave Search 资料进一步验证:GEO / AI Visibility 已有专门平台、SEO 平台入场、行业文章和学术研究支持。
本项目建议进入 小步立项候选,但第一阶段不建议直接做完整 SaaS 平台。更优路径是从 AI 可见性审计报告 切入:用半自动方式为 3 个品牌做样例审计,验证客户是否愿意为“AI 答案中的品牌存在感、引用来源、竞品对比和优化建议”付费。
| 字段 | 内容 |
|---|---|
| 话题群 | Tranfu AI机会 |
| 项目标题 | 生成式引擎优化,GEO/AEO |
| 当前阶段 | discussing |
| 消息规模 | 6 条消息 / 4 条人类消息 / 2 条 App 分析 |
| 资源规模 | 去重资源 8 个;项目表统计 resource_count=30,主要来自同一分析卡片中的 URL 重复展开 |
| 项目档案 | [内部链接已脱敏] |
【事实】用户在 Lark 话题中明确提出:
生成式引擎优化,GEO/AEO。 通过技术 + 内容手段,让品牌/产品在生成式 AI 搜索/对话产品(豆包、DeepSeek、Kimi、元宝、文心一言、夸克 AI、百度 AI 搜索、通义、ChatGPT 等)回答用户问题时,被引用、被推荐、被排在显著位置的一整套优化服务。 包含:AI 可见性监测工具、AI 答案优化代运营服务、为 GEO 服务的内容生产、为 AI 模型抓取做的网站/数据结构改造。
【事实】用户随后追问:
现在 geo 有什么成熟的工具和平台?
这说明 Lark 内部需求不是泛泛“市场调研”,而是已经指向:
是否存在成熟工具和平台;
这个方向能否产品化或服务化;
应该如何理解 GEO/AEO 的市场阶段。
【事实】话题内 AI 初步分析已经形成几个判断:
GEO 是真实的新兴市场,处于 0 到 1 早期;
本质是 SEO、品牌监测、内容营销、PR、AI 搜索可见性的交叉;
短期机会在监控和诊断,中期机会在内容优化工作流,长期机会在“AI 搜索时代的 Semrush / Ahrefs”;
已出现专门做 AI Search Visibility / GEO 的平台。
【事实】当前 Lark 话题没有明确反对意见或分歧。
【推断】缺少分歧不代表需求强验证完成,只说明话题还处在早期研究阶段。下一步应主动引入客户视角和反例:SEO/品牌团队是否愿意付费、是否信任 AI visibility 指标、是否认为传统 SEO 工具已经足够。
【事实】话题中已提供/提及的去重资源包括:
Profound:https://www.tryprofound.com/
Scrunch:https://scrunch.com/
AthenaHQ:https://athenahq.ai/
Peec AI:https://www.peec.ai/
Promptwatch:https://promptwatch.com/
Otterly:https://otterly.ai/
Goodie GEO tools:https://higoodie.com/
Writesonic GEO tools:https://writesonic.com/blog/generative-engine-optimization-tools
【推断】Lark 证据已经足以证明:团队内部对 GEO/AEO 有明确需求描述、工具调研意图和资源线索;但尚不足以证明:客户愿意付费、国内市场已经成熟、某个产品形态一定成立。
AI 工具/B2B SaaS/品牌团队是否真的在意“AI 答案里有没有我”;
客户愿意为一次性审计报告付多少钱;
客户是否需要月度监测,还是只需要一次诊断;
中文 AI 搜索/豆包/Kimi/DeepSeek/夸克等入口是否已经影响真实购买决策;
Semrush、Ahrefs、HubSpot、SE Ranking 等大平台入场后,独立小团队还能切哪一段。
Lark 证据:L3-
原因:有明确用户发起、多轮追问、多个外部工具资源和 AI 分析,但还没有客户访谈、试用、付费、负责人和执行资源。
本报告中的 GEO/AEO 包含:
Generative Engine Optimization:生成式引擎优化;
Answer Engine Optimization:答案引擎优化;
AI Search Visibility:AI 搜索可见性;
LLM Visibility / LLM SEO:大模型答案可见性;
Brand Visibility in AI Answers:品牌在 AI 答案中的提及、引用、推荐、语义位置;
AI Overviews / Perplexity / ChatGPT / Gemini 等答案入口中的品牌监测和优化。
不包含:
传统关键词 SEO 的完整替代;
纯内容代写工具;
没有品牌监测、引用分析或答案测试能力的泛 AI 写作工具。
这是 AI Opportunity Radar 的项目机会评估,目标不是写一篇 SEO 科普文,而是判断:
这个方向是否值得现在投入验证? 应该切哪个细分场景? MVP 应该怎么做? 哪些风险会让项目失败?
本次使用 Brave Search 补充检索,重点覆盖:
Search Engine Land: What is Generative Engine Optimization;
Semrush: Generative Engine Optimization / AI Visibility Toolkit / AI Overviews study;
Profound: AI Search visibility platform;
Peec AI: AI search analytics for marketing teams;
Otterly.AI: AI search monitoring across ChatGPT、Perplexity、Google AI Overviews、Gemini、Copilot;
Scrunch AI: brand presence / AI customer experience / AI search visibility;
arXiv: GEO 相关论文与测量框架;
eMarketer / Search Engine Land / GoodFirms / SEO 工具文章关于 AEO/GEO 与 zero-click、AI Overviews 的资料。
传统搜索链路是:
用户搜索关键词 → 搜索引擎返回网页列表 → 用户点击网站 → 品牌获得流量
AI 搜索链路正在变成:
用户直接提问 → AI 综合多个来源生成答案 → 用户在答案中完成认知/比较/决策
这改变了品牌增长的核心问题。
过去企业问:
我的网页在 Google 第几名?
现在企业还必须问:
AI 回答里有没有我? AI 有没有正确描述我? AI 推荐竞品时为什么没有我? AI 引用了哪些来源? 我的官网/文档/内容能不能被 AI 理解和引用?
所以 GEO/AEO 的本质不是“SEO 新名词”,而是一个新的品牌分发与信任入口。
GEO 关注如何提升内容和品牌在生成式 AI 引擎中的可见性。
核心指标包括:
Brand mention rate:品牌出现率;
Citation share:引用占比;
Recommendation share:推荐占比;
Sentiment / framing:AI 如何描述品牌;
Competitor comparison:与竞品相比谁被推荐;
Source attribution:AI 引用了哪些页面或资料;
Query coverage:哪些用户问题能触发品牌出现。
AEO 关注让内容更容易成为答案引擎的可引用材料。
典型优化动作:
FAQ / 问答化结构;
清晰的实体描述;
schema markup;
引用、数据、定义、对比表;
专家观点和权威来源;
内容更新和事实一致性;
页面结构更适合被 AI 摘要。
从产品角度,“GEO/AEO”是行业方法论,“AI Visibility”更适合做用户价值表达。
客户更容易理解:
你的品牌在 AI 答案里是否可见?
而不是:
你需要做生成式引擎优化。
Google AI Overviews、Perplexity、ChatGPT Search、Gemini、Copilot 等入口把搜索结果从“链接集合”变成“答案集合”。Semrush 等 SEO 平台已经开始追踪 AI Overviews、AI Visibility Toolkit 等指标,说明传统 SEO 工具也在将 AI 搜索纳入核心工作流。
判断:上升趋势,强度高。
当用户不点击网页也能得到答案时,传统流量指标会变弱。企业即使自然排名不错,也可能在 AI 答案里不可见;反过来,被 AI Overview / Perplexity / ChatGPT 引用或推荐,可能成为新的品牌曝光和信任入口。
判断:上升趋势,强度高。
Brave 检索显示,AI Visibility / GEO 工具已出现多个玩家:
Profound:企业级 AI 搜索可见性与需求洞察;
Peec AI:面向营销团队的 ChatGPT、Perplexity、Gemini 品牌表现分析;
Otterly.AI:跨 Google AI Overviews、ChatGPT、Perplexity、Gemini、Copilot 的自动监测;
Scrunch AI:品牌在 AI 搜索/AI customer journey 中的表现和内容缺口;
Semrush AI Visibility Toolkit:传统 SEO 平台进入 AI 可见性工具;
SE Ranking / Writesonic / Gauge / Evertune 等也在布局。
判断:市场教育加速,竞争升温,强度中高。
arXiv 和 KDD 相关论文已经围绕 GEO、citation selection、citation absorption、GEO benchmark、AI search visibility 等进行研究。这说明该方向不是单纯营销包装,而是信息检索范式变化后的真实问题。
判断:早期标准化信号,强度中。
| 用户 | 购买动机 | 预算来源 |
|---|---|---|
| B2B SaaS / AI 工具公司 | 用户问 AI“推荐哪个工具”时希望被提及 | 增长 / SEO / 内容营销 |
| SEO / 内容营销团队 | 传统 SEO 指标不足,需要 AI visibility 指标 | SEO 工具 / 内容预算 |
| 品牌 / PR 团队 | 关心 AI 如何描述品牌、是否误读、是否推荐竞品 | 品牌 / 公关预算 |
| 数字营销代理商 | 需要向客户提供新型服务包 | 客户项目预算 |
| 创业公司 / 独立产品 | 需要知道 AI 是否理解自己的定位 | 增长实验预算 |
投资机构研究团队;
垂直行业咨询公司;
电商/消费品牌;
教育、医疗、金融等高信任行业;
跨境品牌和出海 SaaS。
用户不是为了“学习 GEO”付钱,而是为了回答这几个问题付钱:
当用户问 AI 推荐某类产品时,有没有我? 竞品为什么出现,我为什么没有出现? AI 有没有错误描述我的产品? 我应该改哪些官网/文档/内容,才能提高被引用概率? 一个月后我的 AI 可见性有没有提升?
代表:Profound、Evertune、Scrunch AI。
特点:
面向企业品牌;
覆盖多模型、多 prompt、多竞品;
提供 dashboard、benchmark、insight;
可能收费较高。
优势:企业客户、数据产品化、监测体系完整。
弱点:价格高、复杂度高、对小品牌/中文市场不一定友好。
代表:Peec AI、Otterly.AI、Promptmonitor、SE Visible 等。
特点:
入门价格更低;
支持 ChatGPT / Perplexity / Gemini / Google AI Overviews;
更适合营销团队、代理商、小品牌试用。
优势:上手快、价格低、教育成本低。
弱点:容易同质化;报告深度和优化建议可能不足。
代表:Semrush、Ahrefs、SE Ranking。
特点:
在传统 SEO 数据和客户基础上增加 AI visibility;
能整合 keyword、ranking、citation、AI Overview 数据。
优势:已有客户、已有预算、已有工作流。
弱点:AI 原生体验可能不如新创公司;中文/垂直场景可能滞后。
特点:
提供 GEO/AEO 审计、内容改造、PR/引用策略;
可能按项目收费。
优势:适合早期客户教育,能卖高客单服务。
弱点:交付重,规模化差。
| 维度 | 强度 | 判断 |
|---|---|---|
| 新进入者 | 高 | LLM + 搜索 API 让初版监测工具门槛不高 |
| 替代品 | 中高 | SEO 平台、内容平台、代理商都可扩展 |
| 买方议价 | 中 | 客户愿意试,但预算归属仍在形成 |
| 供应商议价 | 中 | 模型和搜索接口成本可控,但采样稳定性重要 |
| 行业内竞争 | 中高 | 2025-2026 年产品会快速变多 |
结论:这是一个“有机会但必须快切细分”的市场。不能做泛泛的 GEO 平台,必须选择差异化入口。
不知道自己是否被 AI 提及:AI answer 入口不可见;
不知道竞品为什么被推荐:缺竞品对比;
不知道 AI 是否错误描述自己:品牌事实不一致;
不知道该优化什么内容:缺行动建议;
无法证明 GEO/AEO 投入有效:缺前后对比指标。
| 机会 | 痛点强度 | AI 解决难度 | 判断 |
|---|---|---|---|
| AI 可见性审计报告 | 高 | 中 | 黄金切入点 |
| 竞品 AI 推荐份额监测 | 高 | 中 | 高价值,可做成订阅 |
| 官网/文档 AEO 改造建议 | 中高 | 中 | 适合服务化交付 |
| 全自动 GEO SaaS 平台 | 高 | 高 | 长期方向,不适合第一步 |
| 面向所有行业的泛 GEO 内容生成 | 中 | 低 | 同质化风险高 |
为一个品牌生成 AI 搜索可见性审计:
品牌名 + 官网 + 竞品 + 目标 query → 多 AI 引擎采样 → 品牌/竞品出现率 → 引用来源 → AI 描述准确性 → 内容缺口 → 30 天优化建议
不需要一开始做复杂 SaaS;
可手动/半自动交付;
客户容易理解;
能验证付费意愿;
结果适合展示样例。
AI 工具;
B2B SaaS;
出海工具;
SEO agency;
正在做内容营销的创业公司。
按周/按月监测固定 query 下的品牌表现。
核心指标:
mention rate;
[已脱敏] share;
citation share;
sentiment;
competitor rank;
source changes;
query coverage。
在审计报告验证有客户愿意持续关注后,再做订阅看板。
把客户现有官网、文档、博客改造成 AI 更容易引用的内容结构。
输出:
FAQ 结构;
comparison pages;
stats / quotes / definitions;
schema 建议;
missing topics;
external citation plan。
效果归因难,需要与监测指标绑定。
适合早期验证。
可能价格:
轻量版:¥999 - ¥2999 专业版:¥5000 - ¥20000 企业版:定制报价
交付物:
AI 可见性评估;
竞品对比;
query 列表;
引用来源;
错误描述;
内容缺口;
30 天行动计划。
适合中期产品化。
按以下维度收费:
品牌数;
query 数;
竞品数;
AI 引擎数;
采样频率;
报告深度。
卖给代理商:
让 SEO/内容/品牌代理商用我们的模板和工具,为客户交付 GEO/AEO 报告。
优点:分发更快。
缺点:需要模板化和白标能力。
反共识判断:GEO/AEO 不是 SEO 的子集,而是品牌信任入口变化。
SEO 关注排名和点击,GEO/AEO 关注 AI 答案中的存在感、引用、语义位置和推荐权重。即使网站排名第一,也可能在 AI 答案中不可见。
置信度:高。
反共识判断:内容数量不是关键,AI 可引用性和实体可信度才是关键。
AI 更需要清晰的事实、结构化描述、比较信息、权威引用、数据和一致性。低质量内容堆量可能无效,甚至让 AI 对品牌产生错误理解。
置信度:中高。
反共识判断:早期最佳形态可能是“审计报告 + 咨询服务”,不是 SaaS。
因为客户还在形成问题意识。先用报告教育市场、验证付费、沉淀指标,再抽象成产品,比直接做 SaaS 更稳。
置信度:高。
项目类型:commercial_product + research_probe + internal_initiative。
证据等级:L1+。已有公开竞品、SEO 平台入场、学术研究、用户问题,但尚缺真实客户访谈和付费验证。
| 结论 | Lark 证据 | 外部证据 | 类型 | 置信度 | 备注 |
|---|---|---|---|---|---|
| GEO/AEO 是真实新兴方向 | 用户明确提出完整定义,并追问成熟工具 | Search Engine Land、Semrush、eMarketer、GEO 论文均在讨论 | 事实+推断 | 高 | 不是凭空概念 |
| 已有可对标工具 | Lark 资源包含 Profound、Scrunch、Peec、Otterly 等 | Brave Search 进一步发现 Evertune、SE Ranking、HubSpot AEO Grader 等 | 事实 | 高 | 工具生态早期但已商业化 |
| 最佳切口不是直接做 SaaS | Lark 需求是“调研工具/平台”,还不是购买软件 | 外部工具多,竞争升温,客户教育仍早 | 推断 | 高 | 先做审计报告更稳 |
| 中文市场机会存在但未验证 | 原始需求点名豆包、DeepSeek、Kimi、元宝、夸克等 | 外部资料多偏英文/海外平台 | 推断 | 中 | 需要中文品牌样例测试 |
| 可以进入小步立项候选 | Lark 有多轮需求+资源+分析 | 外部市场、竞品、SEO 平台入场支持 | 观点 | 中高 | 仍需付费验证 |
Lark 证据等级:L3- 外部证据等级:L2 综合证据等级:L2+/L3-
说明:
Lark 层面强于普通观察:有明确需求定义、多轮追问、工具资源和初步分析;
外部层面强于概念:已有多个产品化平台和传统 SEO 平台入场;
但尚缺客户访谈、试用行为和付费信号,所以不能判为 L4。
| 维度 | 权重 | 分数 | 依据 |
|---|---|---|---|
| Demand reality | 16 | 80 | Lark 原始需求明确且有多轮追问;外部品牌/SEO/内容团队痛点明确,但仍需访谈验证预算 |
| AI workflow fit | 12 | 84 | 多模型答案采样、引用分析、内容缺口总结高度适合 AI 工作流 |
| Technical feasibility | 10 | 78 | 可先半自动采样和报告生成,复杂点在稳定监测与反爬/成本 |
| Validation feasibility | 10 | 82 | 7-14 天可做 3 个品牌样例报告验证 |
| Distribution reachability | 10 | 72 | Lark 已点名 AI 产品/品牌场景;AI 工具/B2B SaaS/SEO agency 可作为第一批对象 |
| Business/value recovery | 10 | 74 | 审计报告和月度监测均有付费路径,但价格需验证 |
| Reuse and retention | 8 | 78 | 月度监测、竞品对比、内容改造有复购逻辑 |
| Cost structure | 8 | 70 | 模型/API 成本可控,但多引擎采样需要成本管理 |
| Risk and responsibility | 8 | 72 | 风险中等,主要是数据准确性、夸大承诺、平台波动 |
| Tranfu fit | 8 | 88 | 与 AI Opportunity Radar、研究报告、AI 工具生态高度匹配 |
Lark 证据等级:L3- 外部证据等级:L2 综合证据等级:L2+/L3- 状态:小步立项候选,先做 7-14 天样例验证
| Gate | 结果 |
|---|---|
| User gate | 通过:B2B SaaS / AI 工具 / SEO 团队 / agency |
| Demand gate | 部分通过:痛点明确,但付费意愿需验证 |
| AI-fit gate | 通过:AI 适合采样、归纳、对比、建议生成 |
| Responsibility gate | 通过:不涉及高危专业决策,但需避免夸大“保证排名” |
选择 3 个品牌:
一个 AI 工具;
一个 B2B SaaS;
一个中文/出海产品。
每个品牌准备:
官网;
3-5 个竞品;
20 个目标 query;
目标市场/语言。
覆盖:
ChatGPT;
Perplexity;
Gemini;
Google AI Overviews;
Claude / Copilot 可选。
采集:
品牌是否出现;
出现位置;
是否推荐;
是否引用;
引用来源;
描述是否准确;
竞品出现情况。
输出:
AI Visibility Score;
query coverage;
competitor share;
citation source map;
brand misunderstanding list;
content gap;
30 天优化计划。
找 5-10 个潜在客户/朋友公司看样例报告。
验证问题:
是否理解这个报告价值;
是否愿意每月看;
是否愿意为一次性报告付费;
最想看哪 3 个指标;
是否愿意提供官网/竞品/query 做测试。
如果反馈积极:
固化报告模板;
制作 landing page;
形成第一个可销售服务包。
品牌名 官网 URL 产品一句话 竞品列表 目标用户 目标 query 列表 目标 AI 引擎 目标市场/语言
AI Visibility Score 品牌出现率 竞品推荐份额 引用来源 错误描述 内容缺口 AEO 改造建议 30 天行动计划
Query 管理;
多 AI 引擎采样;
答案解析;
品牌/竞品识别;
引用来源提取;
报告生成;
历史对比。
第一版可以半自动,不需要全自动平台。
假设 2 年后项目失败,最可能原因:
直接做 SaaS,看板没人持续用;
客户只觉得“有趣”,但不愿付费;
Semrush / Ahrefs / SEO 平台快速覆盖主流需求;
采样波动大,客户不信数据;
无法证明优化动作带来可见性提升;
只做监测,没有行动建议;
中文/国内场景 AI 搜索习惯不足,需求释放慢。
我会改变看法的触发条件:
10 个潜在客户看完样例报告后无人愿意继续试用;
客户只关心传统 SEO,不关心 AI 答案;
采样结果高度不稳定,无法形成可信指标;
大平台低价提供足够好能力,导致独立产品价值被压缩。
GEO/AEO 是当前三个项目中最适合先做样例验证的方向之一。它的优势是 Lark 话题证据相对最完整:有明确需求定义、多轮追问、资源列表和 AI 初步分析;短板是还没有客户访谈和付费验证。
推荐路线:
AI 可见性审计报告 → 3 个品牌样例测试 → 5-10 个客户访谈 → 标准化报告模板 → 月度监测服务 → 轻量 SaaS 看板
不建议路线:
一开始做大而全 GEO 平台 一开始承诺提高排名 一开始只做内容生成 一开始不做竞品对比和引用来源
唯一主线下一步:
选 3 个品牌,做 AI Visibility Audit 样例报告,并把结果回填到 Lark 话题:每个品牌至少记录 20 个 query、3-5 个竞品、5 个 AI 入口、客户反馈和是否愿意付费。
Search Engine Land: Generative engine optimization: How to win AI mentions
Semrush: Generative Engine Optimization practical guide
Semrush: AI Visibility Toolkit / AI Overviews study
Profound: Optimize Your Brand's Visibility in AI Search
Peec AI: AI Search Analytics for Marketing Teams
Otterly.AI: AI Search Monitoring and LLM Monitoring
Scrunch AI: Boost Brand Presence in AI Search
arXiv: Generative Engine Optimization and GEO measurement research
eMarketer: GEO and AEO in AI search
SE Ranking / Gauge / Evertune / Writesonic industry comparisons
| 类型 | 内容 |
|---|---|
| Lark 话题群 | Tranfu AI机会([已脱敏]) |
| 相关 Signals / Evidence Links | 后续由 03 数据看板同步补齐 |
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
让品牌/产品在 ChatGPT、Perplexity、Gemini、Google AI Overviews、豆包、DeepSeek、Kimi 等 AI 答案引擎中——被提及、被引用、被推荐——的可见性监测与内容优化服务,优先从"AI 可见性审计报告"切入客户验证市场。
| 优先级 | 用户 | 购买动机 | 预算来源 |
|--------|------|----------|----------|
| 内部排序 | B2B SaaS / AI 工具公司 | 用户问 AI "推荐哪个工具"时希望被提及 | 增长/SEO/内容营销 |
| 内部排序 | SEO / 内容营销团队 | 传统 SEO 指标不足,需要 AI visibility 指标 | SEO 工具/内容预算 |
| 内部排序 | 品牌 / PR 团队 | 关心 AI 如何描述品牌、是否误读、是否推荐竞品 | 品牌/公关预算 |
| 内部排序 | 数字营销代理商 | 需要向客户提供新型服务包 | 客户项目预算 |
| 内部排序 | 创业公司 / 独立产品 | 需要知道 AI 是否理解自己的定位 | 增长实验预算 |
| 内部排序 | 出海中国品牌 | AI 搜索(Perplexity/ChatGPT/Gemini)在海外影响买决策 | 出海营销预算 |
不知道自己是否被 AI 提及:AI answer 入口不可见,传统 SEO 监控无法覆盖
不知道竞品为什么被推荐:缺 AI 答案中的竞品对比数据
不知道 AI 是否错误描述自己:品牌事实不一致,影响信任
不知道该优化什么内容:官网/文档/博客的结构、引用、schema 是否被 AI 理解
无法证明 GEO/AEO 投入有效:缺前后对比指标和行业基准
消息/资源:6 条消息(4 条人类 + 2 条 AI 分析),30 个资源(含 8 个去重工具/平台链接)
话题发起人:内部成员
原始需求摘录:
"通过技术 + 内容手段,让品牌/产品在生成式 AI 搜索/对话产品回答用户问题时,被引用、被推荐、被排在显著位置的一整套优化服务。包含:AI 可见性监测工具、AI 答案优化代运营服务、为 GEO 服务的内容生产、为 AI 模型抓取做的网站/数据结构改造。"
后续追问:"现在 geo 有什么成熟的工具和平台?"
话题证据等级:L3-(有明确需求定义、多轮追问、工具资源、AI 分析,但缺客户访谈和付费验证)
当前状态:验证中 / 小步立项候选
去重资源:Profound、Scrunch、AthenaHQ、Peec AI、Promptwatch、Otterly、Goodie GEO、Writesonic GEO
GEO / AI Visibility 已不是概念,Search Engine Land、Semrush、eMarketer 等主流 SEO/营销媒体持续覆盖
传统 SEO 平台正入场:Semrush AI Visibility Toolkit、SE Ranking AI Overviews
多个独立平台已产品化:Profound(企业级)、Peec AI(营销团队版)、Otterly.AI(多引擎自动监测)
arXiv 已出现 GEO 论文、测量框架和 benchmark(citation selection、citation absorption)
AI Overviews、Perplexity、ChatGPT Search 正在改变搜索行为,zero-click 模式放大品牌可见性价值
中文市场:豆包/DeepSeek/Kimi/元宝/夸克/百度AI搜索等入口增长快,但外部资料多偏英文
| 梯队 | 代表 | 特点 |
|------|------|------|
| 第一梯队:企业级 AI Visibility 平台 | Profound、Evertune、Scrunch AI | 多模型、多 prompt、企业客户 |
| 第二梯队:自助式监测工具 | Peec AI、Otterly.AI、SE Visible | 低价、易上手,适合小团队 |
| 第三梯队:传统 SEO 平台扩展 | Semrush、SE Ranking、Ahrefs | 已有客户和预算,AI 原生体验可能不足 |
| 第四梯队:Agency/服务商 | 各类 SEO 代理 | 交付重,规模化差,但能卖高客单服务 |
不要直接做完整 SaaS;先为人品牌做 7-14 天样例验证。
输入:
品牌名 + 官网 URL + 产品一句话
竞品列表(3-5 个)
目标 query 列表(20 个)
目标 AI 引擎(ChatGPT / Perplexity / Gemini / AI Overviews / 可选中文入口)
市场/语言
输出:
AI Visibility Score(品牌出现率、推荐份额、引用来源)
竞品对比(谁被推荐、谁没出现)
品牌描述准确性与误读清单
内容缺口与 AEO 改造建议
30 天行动计划
第一版可半自动交付,不需要全自动平台。
选 3 个品牌(一个 AI 工具、一个 B2B SaaS、一个中文/出海产品)
7 天完成多引擎采样 + 报告生成
找 5-10 个潜在客户看样例报告,验证:
是否理解报告价值
是否愿意每月看更新
是否愿意为一次性报告付费
最想看哪 3 个指标
| 风险 | 可能性 | 影响 | 缓解 |
|------|--------|------|------|
| 客户觉得"有趣但不付费" | 中高 | 致命 | 先做样例后再收费 |
| Semrush/Ahrefs 快速覆盖 | 中 | 严重 | 聚焦中文/出海差异化 |
| 采样波动大,数据不可信 | 中 | 严重 | 固定 prompt 模板 + 多轮采样 |
| 只做监测没有行动建议 | 中低 | 中 | 审计报告天然包含优化建议 |
| 中文 AI 搜索需求释放慢 | 中 | 中 | 优先英文市场验证,再回归中文 |
我会改变看法的触发条件:
10 个潜在客户看完样例报告后无人愿意继续试用
客户只关心传统 SEO,不关心 AI 答案
采样结果高度不稳定,无法形成可信指标
第 1 步(7 天):选 3 个品牌 → 多引擎采样 → 出样例审计报告 第 2 步(7 天):找 5-10 个潜在客户验证付费意愿 第 3 步:根据反馈固化报告模板 → 制作 landing page → 形成可销售服务包 第 4 步(中期):月度监测订阅 → 轻量 SaaS 看板
不建议的路线:一开始做大而全 GEO 平台 / 承诺提高排名 / 只做内容生成不做竞品对比
Search Engine Land: "Generative engine optimization: How to win AI mentions"
Semrush: "Generative Engine Optimization practical guide" / "AI Visibility Toolkit"
Profound: https://www.tryprofound.com/
Peec AI: https://www.peec.ai/
Otterly.AI: https://otterly.ai/
Scrunch AI: https://scrunch.com/
arXiv: GEO measurement research / citation selection papers
eMarketer: GEO/AEO in AI search trends
SE Ranking / Gauge / Evertune / Writesonic 行业对比
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
这是 Batch A 里最接近“可以小步立项验证”的方向。理由不是“GEO 概念新”,而是内部话题已经同时出现了:明确需求定义、二次追问、工具/平台资源、以及可半自动交付的服务切口。当前更适合定义为 AI 搜索可见性审计服务,不是先做 SaaS 平台。
我对它的判断是:内部排序 验证中,可用 14 天验证是否从“有趣报告”升级为“愿意付费的增长/品牌预算”。 如果验证失败,多半不是技术问题,而是客户还没把 AI 答案可见性纳入预算。
项目名:生成式引擎优化,GEO/AEO
Lark thread:[已脱敏]
更新策略:high
负责人:内部成员
数据来源:snapshot
消息 / 资源:6 条消息 / 30 个资源
最近话题脉络:先由内部助手解释 GEO = Generative Engine Optimization,即让品牌、产品、网站在 ChatGPT、Perplexity、Gemini、Google AI Overview 等 AI 答案里更容易被提到、引用、推荐;随后用户追问“现在 geo 有什么成熟的工具和平台”,并沉淀出 Profound、Peec AI、Otterly、Scrunch 等工具链。
证据等级:L3-(有需求定义、多轮追问、工具资源和 AI 分析;仍缺客户访谈、真实审计样例和付费验证)
企业级 AI Visibility 平台:Profound、Scrunch、Evertune、AthenaHQ。优势是多模型、多 prompt、企业销售;劣势是对中文/出海中国品牌的本地化语境未必充分。
自助式监测工具:Peec AI、Otterly.AI、Promptwatch、Goodie GEO、Writesonic GEO。优势是上手快、价格低;劣势是很容易停留在 dashboard,缺少“我下一步改什么”的服务闭环。
传统 SEO 平台扩展:Semrush AI Visibility Toolkit、SE Ranking AI Overviews、Ahrefs 潜在扩展。优势是已有 SEO 客户和预算;劣势是 AI 答案监测会被当成 SEO 附属模块,不一定能覆盖中文 AI 入口。
Agency / 咨询替代:SEO 代理商、内容营销顾问、公关公司。它们会把 GEO 包进服务里,但交付质量和数据采样方法不稳定。
客户自助替代:市场团队手工用 ChatGPT / Perplexity / Gemini 搜索品牌和竞品,再整理表格。低成本,但不可重复、不可监测、不可形成前后对比。
MVP:AI 可见性审计报告。
输入保持极窄:品牌名、官网、产品一句话、3-5 个竞品、20 个目标 query、目标语言/市场、3-5 个 AI 引擎。
输出只交付一份可读报告:出现率、推荐份额、竞品对比、引用来源、品牌误读、内容缺口、30 天优化建议。
第一版可以半自动,不需要实时看板。核心不是“抓更多模型”,而是让客户看到:AI 正在如何描述我、推荐谁、为什么推荐竞品、我应该改哪些公开内容。
不做完整 SaaS dashboard。
不承诺“提高 AI 排名”或“保证被 ChatGPT 推荐”。
不先做内容代运营团队。
不做全行业泛化模板,先选 B2B SaaS / AI 工具 / 出海品牌。
不把中文和英文市场混在同一套指标里,避免样本口径混乱。
不做需要大量浏览器自动化和账号池的重型采样系统;先用固定 prompt、固定模型、固定轮次。
Day 1:选 3 个样例品牌:1 个 AI 工具、1 个 B2B SaaS、1 个中文/出海产品;每个品牌列 3-5 个竞品。
Day 2:设计 20 个 query 模板,覆盖“推荐工具”“替代方案”“对比”“某场景最佳选择”“品牌是什么”。
Day 3-4:在 ChatGPT、Perplexity、Gemini / Google AI Overviews、以及 1-2 个中文入口中采样;每个 query 至少跑 3 轮,记录品牌出现、竞品出现、引用来源。
Day 5:产出 3 份审计样例,每份控制在 8-12 页或等效文档长度。
Day 6:找 5 位营销/增长/SEO/创始人角色看报告,访谈他们最关心的指标。
Day 7:复盘是否有继续试用意愿、付费意愿、愿意提供真实品牌数据的客户。
7 天通过门槛:5 位访谈对象中至少 3 位能在 5 分钟内理解报告价值;至少 2 位愿意提供自己品牌做真实审计;至少 1 位愿意为一次性审计或月度监测报价继续聊。
Week 2 前 3 天:把样例报告改成可复用模板,固定指标口径:出现率、推荐份额、引用域名、品牌描述准确性、竞品理由、行动建议。
Week 2 第 4-5 天:对 2 个真实客户/朋友品牌做 concierge 审计,要求对方提供官网、竞品、目标市场。
Week 2 第 6 天:给出 30 天优化建议,并区分“立刻改官网/文档/FAQ”“新增内容”“外部引用建设”。
Week 2 第 7 天:确认是否愿意付费购买第二次复测或月度订阅。
14 天通过门槛:至少 1 个真实品牌愿意付费或明确进入报价流程;客户能指出 3 条以上报告中“以前不知道、但有行动价值”的发现。
如果 10 个潜在客户看完样例后都说“有意思,但不值得付费”,应降级为内容营销服务插件,而不是独立项目。
如果同一 query 多轮采样波动过大,导致品牌出现率不可解释,应暂缓 dashboard 化,只保留定性审计。
如果客户只关心 Google SEO 排名,不关心 AI 答案推荐,应把目标用户从 SEO 团队转向品牌/PR/创始人。
如果 Semrush/Ahrefs 等快速推出足够好、足够便宜的同类功能,应转向中文 AI 入口、出海品牌、以及“审计 + 行动建议”服务差异化。
如果样例报告需要大量人工判断且无法模板化,说明短期更像咨询业务,不适合做高频 SaaS。
立即做 3 个品牌的样例审计,不再继续扩大竞品列表。
固定 query 与采样模板,避免每次报告口径变化。
把报告命名为“AI Search Visibility Audit”,面向增长/品牌预算测试报价。
14 天后根据付费/试用结果决定:升级为月度监测服务,还是降级为机会池。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
本文档主体内容保留原有人工/研究判断,不做自动覆盖。
每日自动维护只更新:项目状态卡、最新进展、数据链接。
评估与判断仅在 Base / Score History 发生变化时更新。
项目定义、MVP、风险判断如需大幅调整,需要人工确认。
更新时间:2026年05月26日 14:29(北京时间)
| 字段 | 内容 |
|---|---|
| 当前阶段 | 项目化待确认 / 轻量研究 |
| 话题发起人 | TranFu 团队 |
| 当前推进人 | TranFu 团队 |
| 最近更新时间 | 2026-06-01 |
| 当前判断 | 比亚迪生态方向有完整调研报告和清晰假设,但更像研究报告转项目的候选项。是否纳入长期项目档案,需要先确认团队是否要持续跟进“车主补能 / 行程规划 / 能源服务”这个方向。 |
| 下一步 | 先做项目化判断:确认目标用户、真实痛点、比亚迪生态接入可行性、已有替代方案和验证样本;通过后再进入正式评估和持续维护。 |
2026-06-01:补齐项目档案维护结构,但保留 manual 策略。当前仅将其标记为“项目化待确认 / 轻量研究”,不自动提升优先级,不自动纳入每日项目维护。
2026-05-22:话题创建并附带 BYD 生态商业机会调研报告,核心假设是以“找充电桩 + 行程规划”为高频入口,以智能补能调度为数据飞轮,评估 V2V / V2G / 应急能源等延展机会。
本项目基于 Lark 话题群中已沉淀的讨论与附件线索,围绕 比亚迪开放平台(D++ / DiLink 生态) 探索商业机会。当前讨论的核心设想不是泛泛做“汽车行业 AI”,而是围绕 比亚迪车主的高频出行与补能场景,寻找一个可商业化、可验证、可持续扩展的服务入口。
当前较清晰的一句话定义是:
以“找充电桩 + 行程规划”为高频入口,以“智能补能调度”为数据飞轮,进一步评估是否存在围绕 V2V / V2G / 应急能源调度等延展价值的商业化机会。
这意味着该项目更像一个 车主服务 / 新能源生态服务 方向,而不是一个纯软件功能点。
比亚迪生态商业机会调研报告根据已落地到本地的 Lark 话题汇总:
当前累计消息数:4 条
人类消息数:3 条
AI / App 消息数:1 条
当前状态:discussing
状态建议:建议进入轻量研究
当前话题中已出现的有效线索包括:
用户明确要求:“在此基础上再做一下市场研究”
话题中已出现附件:BYD生态商业机会调研报告.docx
已有初步方向描述:
找充电桩 + 行程规划
智能补能调度
V2V / V2G / 应急能源等高 ARPU 延展机会
现有讨论至少说明了三件事:
团队并不是想做一个抽象“比亚迪相关项目”,而是在找 车主高频场景切入口。
当前设想已经不是一句空标题,而是已经具备了 产品分层结构雏形。
现阶段仍然缺少最关键的商业验证信息:
具体用户是谁
高频痛点是否足够强
现有替代方案是什么
用户是否愿意付费
所以,当前结论不应是“可以立项”,而应是:
方向值得继续研究,但必须先重构为更具体的用户场景与验证方案。
当前可以把项目定义为:
围绕比亚迪车主在新能源出行过程中的几个关键节点,构建一个从 信息入口 → 决策辅助 → 调度能力 → 高价值延展服务 的产品路径。
找充电桩
路线规划
补能决策
里程/续航焦虑相关辅助
这是最接近日常使用频率、也最容易切入的部分。
根据路线、时间、电量、目的地、排队情况做补能推荐
给出更优的充电方案
帮助用户减少等待、绕路、决策成本
这一层如果成立,才可能真正体现 AI 的价值,而不是普通信息聚合。
V2V(车与车之间的应急供能)
V2G(车与电网互动)
应急能源调度
车主能源服务延展
这一层想象力最大,但距离验证也最远。当前不应该直接拿它当第一阶段产品,而应视为未来延展方向。
比亚迪本身就是中国新能源车最重要的用户群体之一,只要切口成立,潜在市场不是小市场。
对新能源车主来说:
找合适充电桩
判断何时补能
规划远途路线
降低排队与时间损耗
这些都是真实问题,而不是伪需求。
普通 App 可以展示地图和充电站,但 AI 有机会做的是:
结合车况、路线、时间、偏好做推荐
动态重算补能方案
形成用户更信任的辅助决策
这比单纯做“充电站列表”更有机会形成差异。
“比亚迪生态商业机会”这个名字太大,里面可能包含:
车主服务
车后市场
社群
本地生活
充电服务
车机生态
能源服务
如果不收窄,项目就会一直停留在研究阶段。
即使不考虑 AI,也已经有:
地图类服务
充电桩平台
车主社群信息交换
车企官方能力
通用导航工具
所以必须回答:
为什么用户需要一个新的产品,而不是继续用现有组合方案?
目前可以看出 AI“可能有用”,但还没有证明 AI 是这个项目的核心价值,而不是锦上添花。
如果要做得足够深,后续很可能涉及:
车机/开放平台能力接入
充电数据接口
地图与导航数据
生态合作路径
这意味着:
不是单纯做一个前端页面就能解决
后续验证必须尽早碰触“能不能接入”的现实问题
结合当前已存在的机会雷达评估沉淀,本项目当前统一口径应为:
内部评估 / 内部评估:80
正式结论:重构方向
项目阶段:待轻量研究
优先级:内部排序
基础分:65
证据系数 / 完整度:0.9
正式分:59
关键维度:
需求真实性:72
AI 适配:62
验证可行性:70
商业价值:68
因为当前缺的不是想象力,而是:
具体用户画像
高频入口验证
替代方案缺口
真实付费场景
分发/生态接入路径
所以现在更合理的结论不是“推进立项”,而是:
先重构项目定义,再验证是否值得进入正式产品方向。
如果要保留这个方向,我认为最值得保留的不是“大生态”叙事,而是下面这条线:
新能源车主补能与行程规划的智能决策辅助。
原因:
它比“比亚迪生态”更具体;
它比“泛车主服务”更容易验证;
它更容易形成可衡量的价值:
节省时间
减少绕路
提高补能效率
降低决策成本
必须明确:
是日常通勤车主?
是长途出行车主?
是网约 / 运营类用户?
是充电服务运营方?
这几类用户的痛点差异非常大。
“找充电桩 + 行程规划”是否真的是最高频入口? 还是:
补能时机判断
路径重规划
应急能量调度
更有价值?
如果现有地图/充电 App/官方车机已经足够好,那新产品很难成立。
如果只是静态推荐,AI 不一定比规则系统更有优势。必须确认 AI 在什么情况下能显著提高体验和决策质量。
当前不建议继续以“比亚迪生态商业机会调研报告”这种宽标题直接推进产品,而建议收口为:
比亚迪车主补能与行程规划智能助手
面向新能源车主,帮助其在出行过程中更高效地完成:
续航判断
补能节点选择
路线与时间决策
异常情况下的替代补能方案选择
这会让项目从“行业报告型机会”转向“用户问题型机会”,更适合机会雷达继续推进。
优先访谈 3-5 位目标用户,至少覆盖:
日常通勤型新能源车主
中长途出行车主
对补能体验敏感的用户
访谈重点:
他们最常见的补能决策问题是什么
当前靠什么解决
哪些场景最烦
愿不愿意为更省时间/更安心的方案付费
需要明确当前替代组合:
地图导航
充电桩平台
官方车机/官方 App
社群经验
手工决策
然后判断差距到底在哪里。
要尽快回答:
AI 是做解释?
做补能决策?
做动态调度?
做个性化建议?
不能笼统写“AI赋能”。
即使第一版先不深接,也要尽早评估:
后续需要什么开放能力
能否拿到关键数据
是否存在强依赖某个平台的风险
这个方向不建议直接立项,但值得继续保留并进入轻量研究。
有真实场景基础
有一定商业想象力
AI 可能存在价值切入点
但当前定义过宽,关键验证信息不足
不是继续扩写“大生态故事”,而是:
尽快把项目重构为“比亚迪车主补能与行程规划智能助手”,并补足用户、场景、替代方案、生态接入四类关键信息。
明确车主高频入口;
补充比亚迪开放能力、竞品和潜在合作/分发路径;
完成一轮轻量研究后再重新评估。
正式评估:59
正式结论:重构方向
当前阶段:待轻量研究
下一步动作:明确车主高频入口;补充比亚迪开放能力、竞品和潜在合作/分发路径
保留中置信度说明
标注需要补访谈与替代方案研究
保留内部评估:80
同步当前正式结论为“重构方向”
明确“车主服务 / 新能源生态”核心方向
只记录今天完成了哪部分调研
不重复承担长期真相源职责
| 字段 | 内容 |
|---|---|
| 当前数据口径 | 4 条消息 / 3 条人类消息 / 1 条 AI/App 消息 / 16 个资源;其中一条 AI 回复疑似串题,维护时不作为比亚迪方向证据。 |
口径:基于最新项目维护报告、Lark 话题真实数据与可复核公开资料整理;web_search 当前不可用,因此未二次核验的市场判断均按“趋势/假设”保守处理。
围绕比亚迪庞大车主与新能源出行生态,寻找“补能/行程/车主服务/智能座舱内容/开发者工具”的轻量商业机会,但当前应先确认是否项目化,避免误把一次调研当长期项目。
比亚迪新能源车主,尤其是高频通勤、长途自驾、家庭出行用户。
比亚迪生态周边服务商:充电、维修保养、改装、保险、二手车、车品、内容/导航服务。
希望接入车机/智能座舱/车主社群的开发者或本地服务商。
新能源车主仍有补能焦虑:充电桩可用性、排队、价格、路线规划、跨城出行可靠性。
车主服务分散在车机、App、地图、充电平台、社群和本地商家之间。
比亚迪用户基数大,但第三方要进入生态需要明确入口、数据权限和合作模式。
智能座舱应用常见问题是“看起来有入口,但真实使用频次和商业转化不确定”。
内部话题数据
话题负责人:内部成员。
消息/资源:4 / 16。
最近内部摘要包含一个文件:BYD生态商业机会调研报告.docx,随后有“在此基础上再做一下市场研究”。维护报告中还混入了“团队 API Key 管理”的输出摘要,提示当前归档内容可能存在串话/写入错位。
维护报告明确警告:manual update policy,未明确人工批准不要自动写入。
外部资料与趋势
比亚迪在新能源车销量、垂直整合、电池和智能化方面持续扩张,带来庞大车主生态和后市场服务空间。
车企智能化方向集中在智能座舱、驾驶辅助、车机应用、补能网络和 OTA 服务。
中国新能源车主的真实高频需求往往不是“泛车机 App”,而是补能、用车成本、路线、保养、保险、二手残值、社群服务。
官方生态:比亚迪 App、DiLink/智能座舱、官方服务、官方商城、OTA 能力。
地图与补能:高德、百度地图、腾讯地图、特来电、星星充电、云快充、国家电网 e 充电。
车主服务:途虎养车、京东养车、保险平台、二手车平台、车主社群/KOC。
智能座舱内容:车机应用商店、音频/视频/游戏/导航/本地生活服务。
优先从低权限、强需求、可独立验证的场景入手:
比亚迪车主长途补能规划助手:输入车型、出发地/目的地/时间,输出路线、充电点、备用方案、价格与排队风险。
比亚迪车主省钱助手:整合充电价格、保养、保险、轮胎、车品优惠和周期提醒。
车主社群服务雷达:围绕本地车主群,做活动、服务商、团购、口碑榜。
推荐 MVP:长途补能规划助手。它绕开官方深度接入,用户痛点明确,适合用公开地图/充电站信息与车主反馈做早期验证。
访谈 20 位比亚迪车主,区分通勤、网约车、家庭长途、自驾游用户。
收集 10 条真实长途路线,人工生成补能方案,对比高德/百度/官方方案的差异。
在车主群中测试“路线规划 + 备用桩 + 风险提醒”是否被转发/收藏。
指标:方案采纳率、用户是否愿意提前一天咨询、是否愿意为高级规划/会员省钱服务付费。
官方 App/地图平台可能快速覆盖补能规划,第三方缺少数据优势。
充电桩实时状态、排队、故障信息获取难,若数据不准会直接损害信任。
智能座舱开发者机会依赖官方平台政策,非确定性强。
当前内部档案存在串话迹象,若不能确认原始 BYD 报告内容,应暂缓正式评估。
先做档案清洗:确认 BYD生态商业机会调研报告.docx 内容,并剔除维护报告中疑似“团队 API Key 管理”的串话摘要。
把状态保持为“项目化待确认 / manual”,不自动写 Wiki。
用 20 位车主访谈判断优先切口:补能规划、车主省钱、智能座舱应用、车主社群服务。
比亚迪全球官网:https://www.bydglobal.com/
比亚迪中国官网:https://www.byd.com/cn
高德地图新能源充电服务:https://ditu.amap.com/
维护边界:本章节为 2026-06-02 增强分析受控块;后续若有新客户验证、竞品变化或 Lark 话题进展,可替换本章节,不覆盖原始档案正文。
口径:本章节用于替换昨日偏模板化的增强稿表达;基于 Lark 话题真实数据、项目 mapping、既有维护报告与公开竞品格局,强调判断、边界、验证和反证。不覆盖原文其它章节。
这是一个“可能有机会,但档案本身需要先修复”的项目。内部确实出现了 BYD 调研文件和“在此基础上再做市场研究”的请求,但最新维护摘要里混入了“团队 API Key 管理”的市场研究内容,说明归档链路存在串话或错位风险。
所以当前不能直接给高优先级,也不应自动写入 Wiki。最稳妥的判断是:项目化待确认 / manual,先做档案清洗,再决定是否围绕补能、车主服务或智能座舱继续验证。
若原始 BYD 报告确认有效,最值得先测的不是泛“比亚迪生态”,而是 比亚迪车主长途补能规划助手:低权限、强痛点、可通过车主访谈和公开信息验证。
标题:比亚迪生态商业机会
Lark thread:[已脱敏]
更新策略:manual
负责人:内部成员
数据来源:snapshot
消息 / 资源:4 条消息 / 16 个资源
关键内部线索:出现文件 BYD生态商业机会调研报告.docx,随后用户要求“在此基础上再做一下市场研究”。
重要异常:维护报告最近摘要中出现“团队 API Key 管理与大模型订阅授权分发”的内容,疑似串话。
证据等级:L2-(有文件和资源,但原始报告内容未复核,且档案存在污染)
官方生态:比亚迪 App、DiLink、官方商城、服务网点、OTA、车主社区。
地图与补能平台:高德、百度地图、腾讯地图、特来电、星星充电、云快充、国家电网 e 充电。
车主服务平台:途虎养车、京东养车、保险平台、二手车平台、本地维修保养商家。
车主社群/KOC:微信群、抖音/小红书车主内容、地方俱乐部、改装/用车经验社群。
智能座舱内容替代:车机应用商店、音频视频 App、导航、本地生活服务。
推荐 MVP:比亚迪车主长途补能规划助手。
只做:
输入车型、出发地/目的地、出发时间、是否带老人孩子、可接受绕路范围。
输出一条主路线 + 2 个备用补能方案。
标注充电点位置、预估到达电量、附近休息/餐饮、可能排队风险、失败备用点。
支持用户反馈:桩是否可用、是否排队、价格、体验。
明确不做:
不做车机应用,不依赖 DiLink 深度权限。
不承诺实时准确的充电桩状态,早期必须标注数据来源和不确定性。
不做全品牌新能源车主平台,先只拿 BYD 车型验证。
不做官方生态合作假设,除非有明确渠道。
不做泛车主商城/车品导购,避免需求发散。
第一步:档案清洗(必须先做)
找到并读取 BYD生态商业机会调研报告.docx。
标记哪些内容来自 BYD 原始调研,哪些是后续 AI 生成,哪些疑似串入 API Key 项目。
清理后再决定是否写入受控增强区块。
第二步:20 位车主访谈
分层:通勤、家庭长途、自驾游、网约车/高频用车、首次新能源车主。
重点问:最近一次补能踩坑、使用哪个 App、是否提前规划、愿不愿意看第三方方案。
第三步:10 条路线人工样例
收集真实路线,用高德/百度/充电平台信息人工生成规划。
与用户现有方案对比:是否更安心、更省钱、更少绕路。
通过门槛:20 位车主中至少 8 位有近期补能焦虑或踩坑;10 条路线中至少 5 条能给出比现有工具更有用的备用方案;至少 3 位愿意下次出行前主动咨询。
如果原始 BYD 调研报告无法复核,项目应保持 manual,不做评估。
如果高德/百度/官方 App 已经满足 80% 需求,第三方规划价值不足。
如果拿不到可信充电桩实时数据,用户只会把它当参考攻略,而不是决策工具。
如果车主痛点更集中在保养、保险、二手残值而非补能,应切换方向。
如果机会依赖比亚迪官方接口/座舱入口,应暂缓,除非有合作资源。
先做档案清洗,剔除 API Key 串话。
将状态维持为“项目化待确认 / manual”,不要自动外部写入。
若 BYD 报告有效,启动 20 位车主访谈,优先验证长途补能。
若补能不成立,再比较“车主省钱助手”和“本地车主社群服务雷达”。
维护边界:本章节为 2026-06-03 质量升级受控块;后续新证据出现时可整体替换本章节。
本档案目前按“研究报告转项目候选”处理,不默认纳入自动每日维护。
负责人默认取 Lark 话题 root message 的 sender;本项目话题发起人为“内部成员”。
当前有一条 AI/App 消息内容疑似串到“团队 API Key 管理”,不得作为比亚迪项目判断依据。
自动维护只允许更新项目状态卡、最新进展、数据链接和维护说明;原有研究正文默认不覆盖。
🛠 核心工具栈: Cursor | Git Worktree | Opus 4.6 & Codex-5.3
🎯 核心目标: 通过“一句话提示词”触发多个 Sub-agent 形成自动化串行执行,实现多任务并行开发。
📂 当前提案: openspec/changes/redesign-skill-card-vertical
0 TASK 0:提案复核
1️⃣ TASK 1:架构师预审 (Architect Review)
2️⃣ TASK 2:提案执行 (Implementation)
/opsx/apply,将打磨后的提案转化为实际代码。3️⃣ TASK 3:代码审查 (Code Review)
git commit 保存初步生成的代码。4️⃣ SubAgent 4:自愈与更新 (Auto-Refinement)
5️⃣ SubAgent 5:收尾与归档 (Archiving)
/opsx/archive,对当前提案进行状态归档。git commit,完成该特性的闭环。当前流水线实现了高度的自动化,但整体运行耗时稍长。
> 时间:2026年3月26日 10:04(北京时间) > 主题:内部助手的任务工作流设计原则、AGENTS.md 与 Skill 的职责边界、为什么默认流程属于上层规则而不是专项技能
最近我们围绕一个问题做了比较深入的讨论:
**“为什么内部助手现在这套默认工作流程,要写在 AGENTS.md,而不是直接做成某个 skill?”*“为什么内部助手现在这套默认工作流程,要写在 AGENTS.md,而不是直接做成某个 skill?”AGENTS.md,而不是直接做成某个 skill?”
这个问题看起来像是文档放哪更合适,但本质上其实是在讨论:
我把这次讨论整理成一篇更完整的文章,方便后续团队统一理解,也方便作为知识库中的长期规则沉淀。
内部助手现在这套默认工作流——比如:
它更适合写在 AGENTS.md,而不是某一个单独的 skill 里。
原因很简单:
这不是某类任务的“专项执行方法”,而是内部助手处理几乎所有任务时的总调度逻辑****总调度逻辑。
换句话说:
AGENTS.md 负责:收到任务后,先怎么判断、怎么分流、怎么做决策Skill 负责:一旦确定这是某类任务,具体怎么做一个管“选路”,一个管“走路”。
AGENTS.md 更像是 AI 助手的工作宪法、操作系统或者岗位说明书。
它适合承载:
这些规则的特点是:
所以这类内容天然适合放在 AGENTS.md。
而 skill 更像一个个专业工具箱或 SOP 模块。
比如:
healthcheck:怎么做健康检查find-skills:怎么搜索可用 skilllark-kb-analysis-writer:怎么导出整库并分析service-guardian:怎么做服务守护compaction-survival:长任务时怎么保持状态不丢它们回答的是:
“当任务已经被识别成某一类后,具体执行方法是什么?”****“当任务已经被识别成某一类后,具体执行方法是什么?”
所以 skill 更适合写“专项执行路径”,而不是负责整个 agent 的总决策逻辑。
这是最关键的一点。
我们现在这套默认流程的前两步就是:
注意这里的逻辑顺序:
**是否调用某个 skill,本身就要先经过上层判断。**是否调用某个 skill,本身就要先经过上层判断。
如果把这套流程写进某个单独 skill,就会出现一个逻辑倒挂:
这就变成自我循环了。
所以像“先判断任务类型”“先查现有能力”“先摸环境”这种规则,必须写在 skill 之上。
而 AGENTS.md 恰好就是那个上层。
这套流程不是只对某一类任务生效。
它同时适用于:
也就是说,它不是某个领域专属,而是内部助手做事的默认脑回路。
这种“共通原则”如果塞进某一个 skill,就会变成局部规则,覆盖范围反而不对。
这套流程本质上是:
这套东西决定的是:
**任务进来后,先走哪条路。**任务进来后,先走哪条路。
而不是某条具体路径内部的步骤。
因此它属于任务路由层任务路由层,不是专项执行层专项执行层。
内部助手并不是一个抽象的工具集合,而是一个带角色约束的助手。
当前体系里,内部助手有:
这些东西不只是“怎么做某件事”,而是:
这更像岗位规则、协作契约,而不是 skill 说明书。
所以应写在 AGENTS.md,而不是写进某个单一 skill。
现实任务经常不是单一归类。
比如一个任务可能同时涉及:
如果没有上层规则,内部助手就很容易:
所以必须有一个写在 skill 之上的“总调度逻辑”,决定:
这正是 AGENTS.md 的职责。
如果专门做一个所谓“intake skill”,里面负责:
那它很快就会变成一个“万能前置 skill”。
问题是:
AGENTS.md 的作用高度重叠结果不是更清楚,而是更容易混乱。
流程会变成:
这在设计上很别扭。
因为本来应该作为 agent 默认脑回路的东西,被额外包成了一个 skill,反而增加了一层形式主义。
并不是所有任务都需要显式走一遍完整 intake。
很多任务其实很轻:
这类任务如果每次都显式调用某个“前置 skill”,系统就会显得过于笨重。
而写进 AGENTS.md,这套规则可以自然地作为默认行为存在:
这更像“会做事的人”,而不是“执行表单流程的机器”。
还有很多任务属于:
如果这类规则不写在上层,而只寄托在某个 skill 上,那一旦任务没命中那个 skill,整套流程就失效了。
所以必须有一个不依赖 skill 是否命中,也能生效的默认行为层****不依赖 skill 是否命中,也能生效的默认行为层。
这层就是 AGENTS.md。
最合理的分工是这样的:
比如:
healthcheck 负责“怎么排查服务健康”lark-kb-analysis-writer 负责“怎么读整库再分析”service-guardian 负责“怎么做守护和 auto-recovery”compaction-survival 负责“长任务如何保存状态、抵抗压缩丢失”可以理解为:
AGENTS.md 是总导演导演决定拍什么、怎么分工;部门负责把自己那段拍好。
也不是。
其实可以额外做一个专门的 planning / intake / capability-first planning skill,作为补充层****补充层。
它适合用在:
但它的定位应该是:
显式规划模块****显式规划模块
而不是:
默认工作流本体****默认工作流本体
也就是说:
AGENTS.md 仍然负责全局默认行为这样两层不会冲突。
因为这次讨论的不是某个专业技能该怎么做,而是一个更上层的问题:
“内部助手以后在面对复杂任务时,默认应该怎么思考、怎么判断、怎么进入执行。”****“内部助手以后在面对复杂任务时,默认应该怎么思考、怎么判断、怎么进入执行。”
这个问题本质上属于:
所以把它写进 AGENTS.md,不仅合理,而且是最清晰的做法。
为什么默认工作流要写在 AGENTS.md,而不是 skill?
因为这套流程决定的是:
**在选 skill 之前,内部助手应该怎么做事。**在选 skill 之前,内部助手应该怎么做事。
而 skill 更适合解决的是:
**当已经确定这是一类任务后,该怎么具体执行。**当已经确定这是一类任务后,该怎么具体执行。
一个是上层总规则,一个是下层专项能力。两者不是对立关系,而是分层关系。
真正成熟的 agent 系统,不是把所有东西都塞进 skill,而是要把:
放在正确的层级上。
这次讨论的价值就在这里:
我们不是只给内部助手增加了一个新流程,而是在逐步把“内部助手怎么工作”这件事,变成一套更清晰、更可维护、也更像真正助理的系统。
基于这次讨论,后续可以继续补两类文档:
如果这两份补上,整个系统的分层会更清楚,内部助手后续也更容易持续优化。
调研日期:2026-03-13
目标:实现 OpenClaw 同时对接 Telegram 和飞书(Lark)
已配置的渠道:
渠道 │ 状态 │ 说明
─────────┼─────────────────┼────────────────────────────────────────────────
Telegram │ ✅ 正常运行 │ 3 个 bot(nexus、xiaoman、polymarket),DM 开放
飞书 │ ⚠️ Webhook 模式 │ 非原生 WebSocket,通过 bridge 中转 当前飞书配置(~/.openclaw/openclaw.json):
{
"feishu": {
"domain": "lark",
"streaming": false,
"blockStreaming": false,
"textChunkLimit": 8000
}
}现有方案:Webhook Bridge
飞书 → Cloudflare Tunnel → bridge.py (localhost:19800) → OpenClaw Gateway (localhost:18789)bridge.py 功能:
问题:
OpenClaw 官方原生支持飞书,通过 WebSocket 长连接接收事件,无需公网暴露。
支持的功能:
在飞书应用权限中批量导入:
{
"scopes": {
"tenant": [
"im:message",
"im:message:send_as_bot",
"im:message:readonly",
"im:chat.members:bot_access",
"im:resource",
"aily:file:read",
"aily:file:write"
]
}
}在 应用能力 → 机器人 中启用并设置机器人名称。
im.message.receive_v1在 版本管理与发布 中创建版本并提交审核。
方式一:CLI 配置(推荐)
openclaw channels add
# 选择 Feishu,输入 App ID 和 App Secret方式二:配置文件
{
"channels": {
"feishu": {
"enabled": true,
"dmPolicy": "pairing",
"accounts": {
"main": {
"appId": "[已脱敏]",
"appSecret": "xxx",
"botName": "内部助手"
}
}
}
}
}飞书国际版(Lark)配置:
{
"channels": {
"feishu": {
"domain": "lark"
}
}
}已有 3 个 Telegram bot:
Bot │ Token │ DM 策略 │ 群聊策略
───────────┼───────────────────────────────┼─────────┼──────────
nexus │ 8605513784:AAHpV9JvZECkHc0... │ pairing │ allowlist
xiaoman │ 8679985454:AAFMmTZSHeBL_... │ open │ open
polymarket │ 8617997098:AAFtetMdfopk_... │ open │ allowlist配置特点:
http://127.0.0.1:7897┌─────────────────────────────────────────────────────────────┐
│ 用户 │
├──────────────┬──────────────────────┬──────────────────────┤
│ Telegram │ 飞书 │ │
│ (原生) │ (原生) │ │
└──────┬───────┴──────────┬──────────┴──────────┬───────────┘
│ │ │
▼ ▼ ▼
┌──────────────────────────────────────────────────────────────┐
│ OpenClaw Gateway │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────┐ │
│ │ Telegram │ │ Feishu │ │ 其他渠道 │ │
│ │ (WebSocket)│ │ (WebSocket)│ │ (WhatsApp等) │ │
│ └─────────────┘ └─────────────┘ └─────────────────────┘ │
└──────────────────────────────────────────────────────────────┘# 配置飞书
openclaw channels add
# 选择 Feishu,输入 App ID 和 App Secret
# 重启 Gateway
openclaw gateway restart
# 查看状态
openclaw gateway status根据需要调整 DM 和群聊策略:
{
"channels": {
"telegram": {
"dmPolicy": "pairing",
"groupPolicy": "allowlist",
"streaming": "partial"
}
}
}飞书群聊支持两种模式:
strict:必须 @ 机器人才回复smart:智能判断,无 @ 也回复有价值的消息{
"channels": {
"feishu": {
"accounts": {
"main": {
"groupPolicy": {
"groups": {
"[已脱敏]": {
"requireMention": true
}
}
}
}
}
}
}
}基于现有配置,内部成员拥有的飞书 Bot:
能力 │ 状态 │ 说明
─────────────┼──────┼─────────────────
接收私聊消息 │ ✅ │ DM 策略:开放
接收群聊消息 │ ✅ │ 需 @ 或在群里
发送消息 │ ✅ │ send_as_bot
发送卡片消息 │ ✅ │ Interactive Card
处理媒体 │ ✅ │ 图片、文件等 能力 │ 权限名称 │ 用途
─────────────┼───────────────────────────────────┼─────────────
读取用户信息 │ contact:user.employee_id:readonly │ 获取用户身份
上传文件 │ im:resource │ 文件上传下载
创建群聊 │ im:chat:create │ 自动建群
@人 │ at:user │ 群聊@功能 类型 │ 支持 │ 说明
───────┼──────┼─────────────────
文本 │ ✅ │ 基础文本消息
富文本 │ ✅ │ post 消息
卡片 │ ✅ │ Interactive Card
图片 │ ✅ │ image 消息
文件 │ ✅ │ file 消息
语音 │ ✅ │ audio 消息 问题 │ 可能原因 │ 解决方案
───────────────┼──────────────────┼─────────────────────────
飞书消息收不到 │ Gateway 未运行 │ `openclaw gateway start`
事件订阅失败 │ WebSocket 未连接 │ 检查 gateway 状态
权限不足 │ 权限未配置 │ 在飞书开放平台添加权限
群聊无法回复 │ 未发布应用 │ 提交审核并发布 # 查看 Gateway 状态
openclaw gateway status
# 查看飞书通道日志
openclaw logs --follow | grep -i feishu
# 测试发送消息
openclaw message send --to <user_id> --message "测试"
# 飞书通道诊断
openclaw doctor 维度 │ Telegram │ 飞书
───────────┼────────────────┼─────────────────────────
集成方式 │ 原生 WebSocket │ Webhook Bridge(需改造)
稳定性 │ 高 │ 中(依赖 bridge)
功能完整性 │ 完整 │ 部分(bridge 限制)
维护成本 │ 低 │ 高(额外服务) 推荐:切换到原生飞书集成
优点:
实施难度:
im:message # 接收消息
im:message:send_as_bot # 发送消息
im:message:readonly # 读取消息
im:chat.members:bot_access # 获取群成员
im:resource # 资源文件
aily:file:read # 读取文件
aily:file:write # 写入文件飞书 App ID: [已脱敏]报告撰写:内部助手 🌾
最后更新:2026-03-13 18:55 GMT+8
你可能见过这样的同事:周报、资料整理、会议纪要都交给 AI 处理,下午 6 点准时下班。而你自己打开 AI,却还是一问一答——背景要反复解释,格式要反复纠正,最后不像在用工具,更像在和 AI 斗智斗勇。
差别不一定在你怎么跟 AI 说话,而在于他用的是能执行任务的 AI Agent(可以理解成“会自己动手干活的 AI 助理”)。
这一章不讲复杂概念,也不写代码。我会带你在 Codex App 里完整走一遍:准备一个空文件夹,做好基本配置,让 Codex 自己安装一个公司 Skill 库(一批别人攒好、打包在一起的方法),最后用一个现成 Skill 帮你审一篇文章。整个过程不涉及命令行,你只需要照着做,看到 Codex 真的动起来、并留下结果,就完成了最重要的一步。
顺利的话,这一篇从准备到跑通大概二三十分钟,中间每一步都有截图,跟着做就行。
这里先假定你已经会注册、安装、登录 Codex,这些不在本文展开。
普通聊天 AI 主要是在“回答”你:你问一句,它答一句;你补一句,它改一点。AI Agent 不一样——你给它一个目标,它会按步骤执行,能检查文件、发起必要的操作、看结果,再把结果写回文件。
| 普通聊天 AI | AI Agent |
|---|---|
| 你问一句,它答一句 | 你给目标,它拆步骤执行 |
| 主要给建议和文本 | 能读文件、跑命令、调用工具、检查结果 |
| 每次都要重新解释背景 | 可以复用已有的工作方法 |
| 更像顾问 | 更像会动手的助理 |
这一章你先不用理解所有细节,先体验一次:把一个明确任务交给 Codex,让它真的动起来。
Agent 会动手,但它不一定知道你的工作习惯:什么内容要先查固定口径、什么情况不能直接改、会议纪要按什么格式归档、复盘里哪些话不能写得太虚。这些通常得你一次次告诉它。
你可以先把 Skill 理解成一份给 Agent 用的工作方法:它会告诉 Agent 什么时候用、按哪几步做、输出什么、遇到什么情况要先停下来问你。
一句提示词解决“这一次怎么说”;一个 Skill 解决“以后都按这套做”。
这一章不会让你写 Skill,你只需要先用 Codex 跑一次安装任务,再亲手试一次它的效果。
Codex 做事需要一个文件夹。它会在这个文件夹里读文件、写文件、执行检查,所以文件夹就是它干活的工作台。没有文件夹,它就只能跟你聊天,发挥不出 Agent 的价值。
怎么管理这些文件夹,有一条简单原则值得从一开始就养成:
一个项目一个文件夹。
这样做有两层好处:
第一次上手,先在桌面新建一个空文件夹,命名为 codex-tranfu-demo。新建文件夹这种事你肯定已经会了,这里不再赘述。需要稍微留意的,是怎么在 Codex 里打开它。
打开 Codex,找类似这样的入口(不同版本叫法略有差异):
选择刚才新建的 codex-tranfu-demo。如果 Codex 提示你确认是否信任这个文件夹,放心确认——它是你刚新建的空文件夹,里面没有任何东西。
打开好之后应该是这样。
打开错了文件夹也不要紧,退出重新选 codex-tranfu-demo 即可。
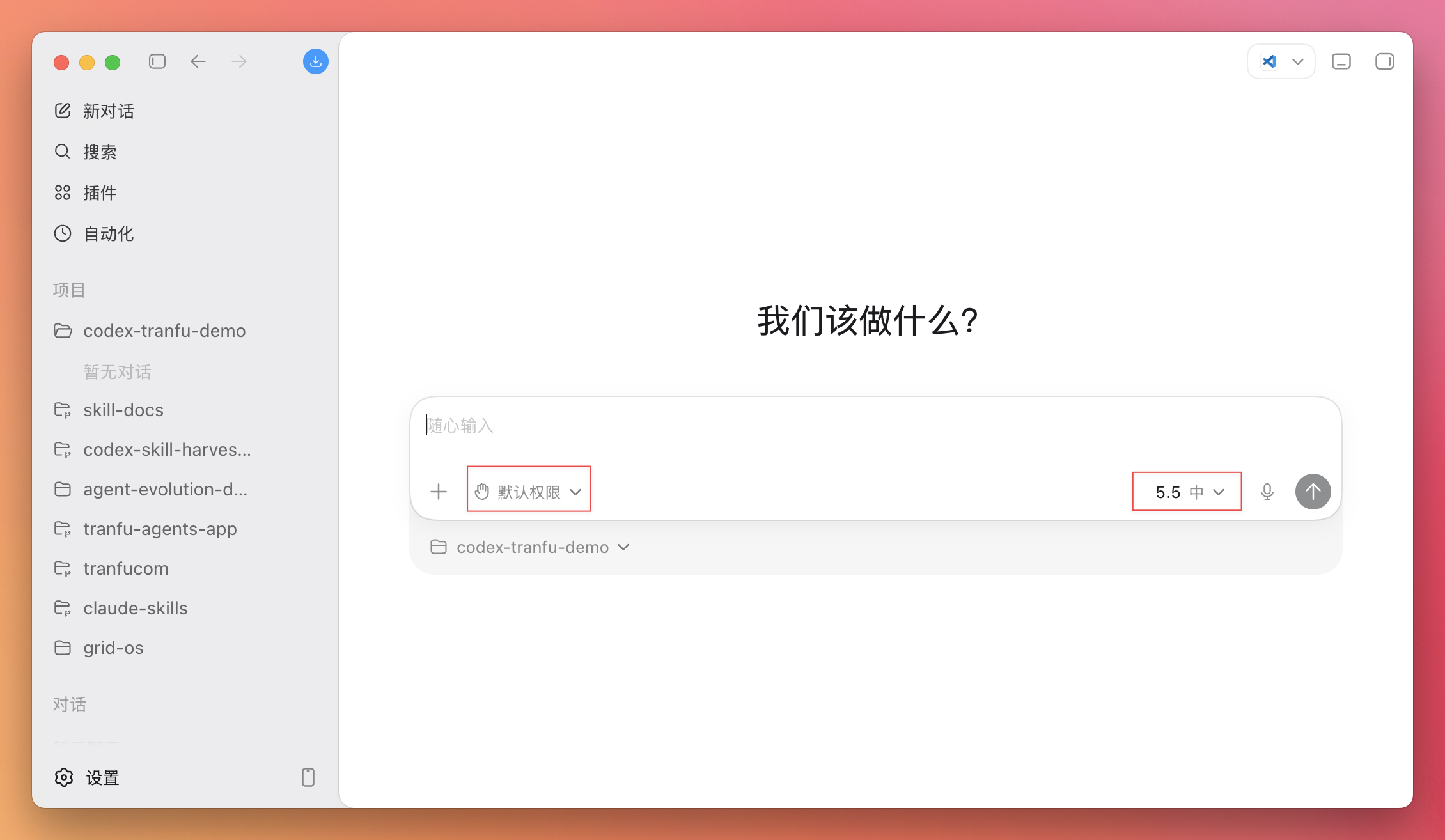
默认设置下,Codex 每做一个动作都可能停下来问你“能不能执行”,模型也未必是最强的那个。第一次上手为了顺畅,建议先调两个地方。
| 设置项 | 建议 | 为什么 |
|---|---|---|
| 权限 | 设为 Full access(完全访问) | Codex 在当前文件夹里读写文件、执行检查时不必每一步都来问你,体验会顺很多。你打开的是一个隔离的空文件夹,就算 Codex 自由发挥,能影响的也只有这个练习文件夹里的内容,碰不到你的正式资料。 |
| 模型 | 选 GPT-5.5,推理强度选 Extra High,速度选 Fast | 任务越是多步骤,模型的推理能力越关键。推理强度拉到 Extra High,Codex 拆解和执行任务时更稳,少走弯路。以 100 美元的 Pro 套餐为例,5 小时的用量基本上是用不完的,除非你同时开好几个任务一起跑。第一次上手,放心用最好的配置。 |
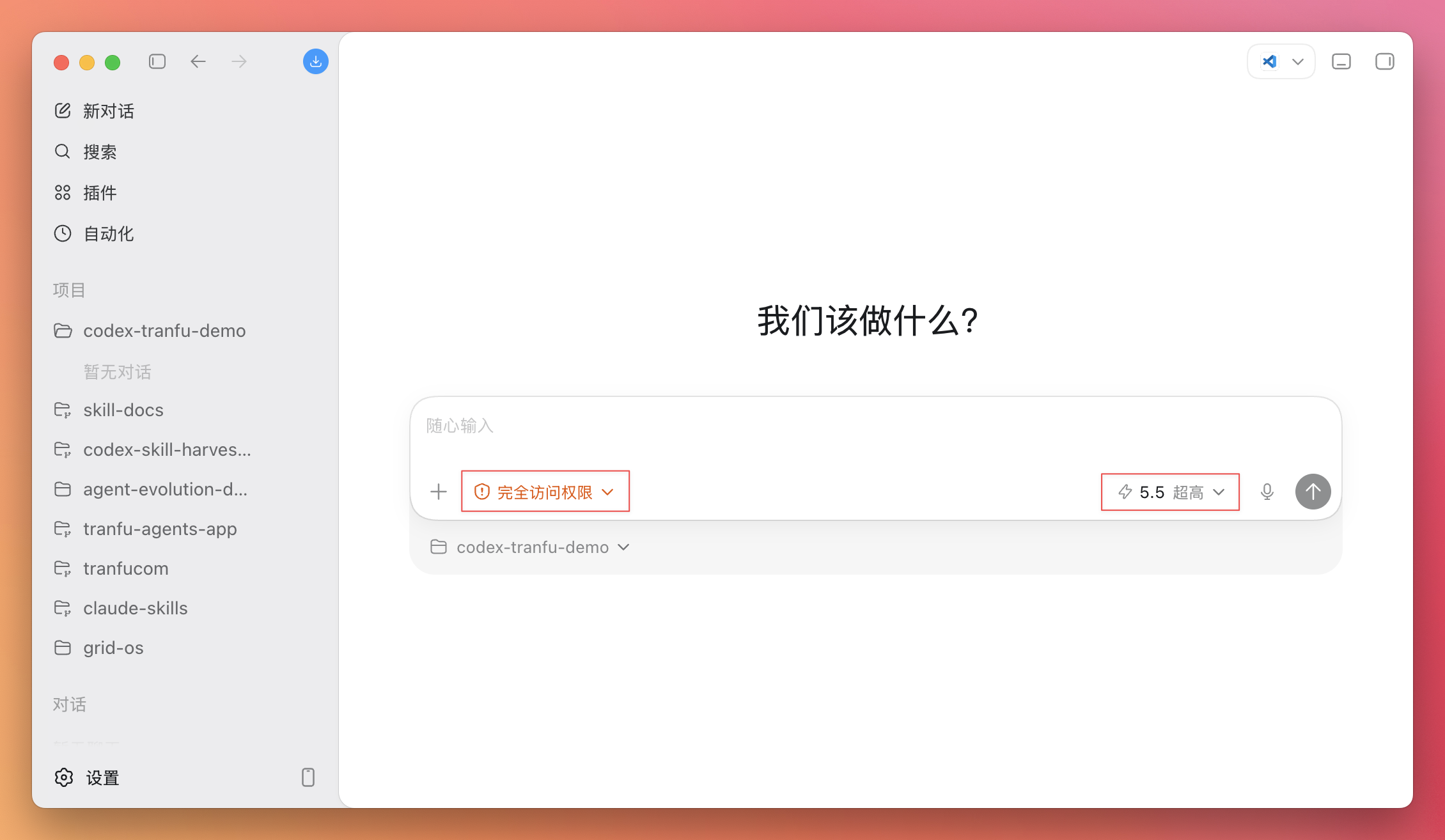
配置好之后,后面 Codex 执行任务时基本不会再频繁打断你。它仍然会把每一步显示出来,你照样能看着它做事——如果哪一步看起来不对劲,随时可以喊停。
想用好 Skill,一个准确、常用、好维护的 Skill 仓库很重要。你不需要自己一个个去写、去攒——直接装一个现成的库,里面别人打磨好的方法就都能用了。这里用我们公司日常在用的 Skill 库做演示。
你只需要把下面这句话复制给 Codex:
请阅读 https://github.com/tranfu-labs/tranfu-skills/blob/main/INSTALL.md 并按文档步骤帮我安装公司 skill 库.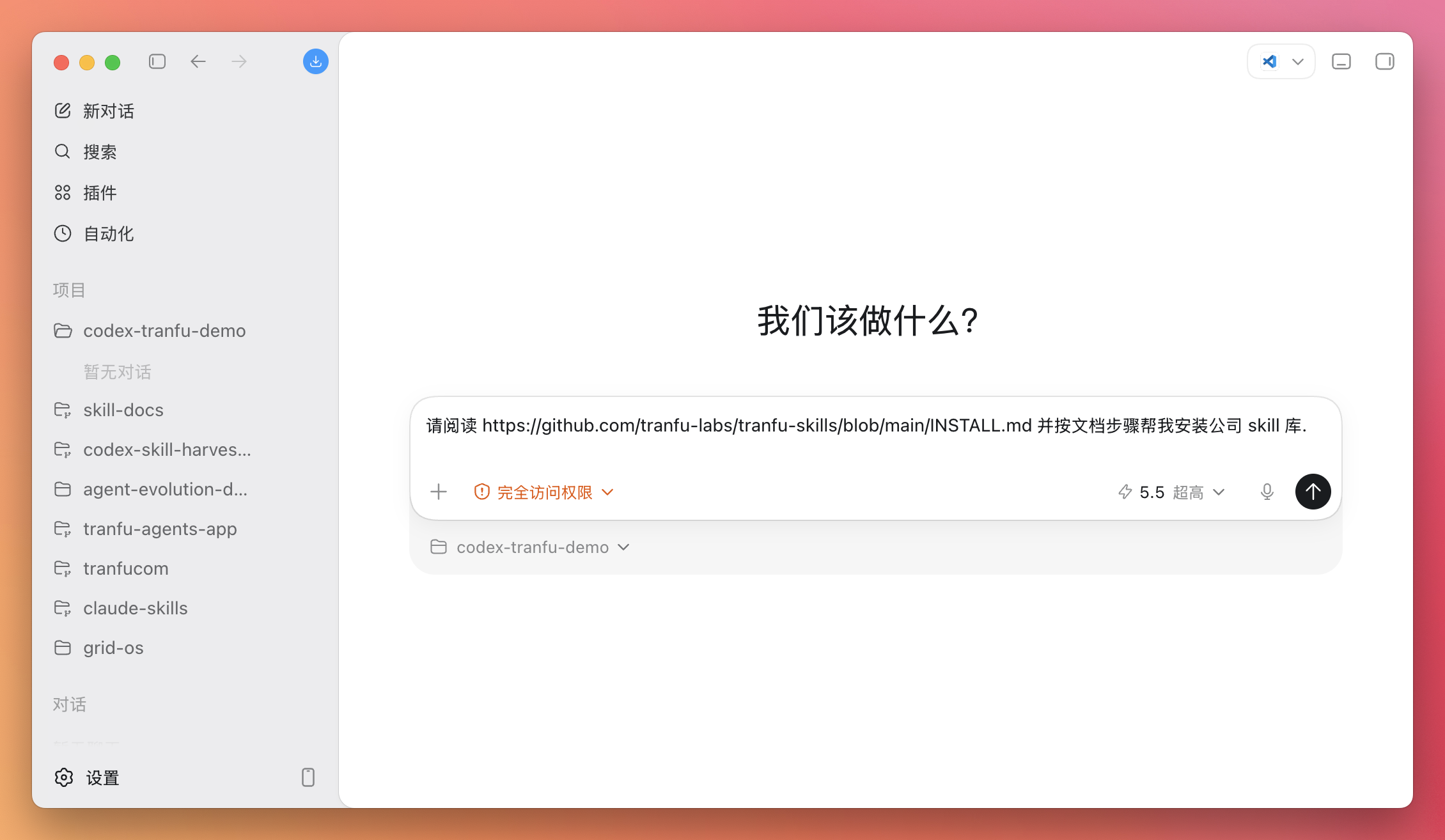
发出去后,Codex 会按文档一步步来:
因为你已经开了 Full access,它通常不必再来征求许可,会自己走完。
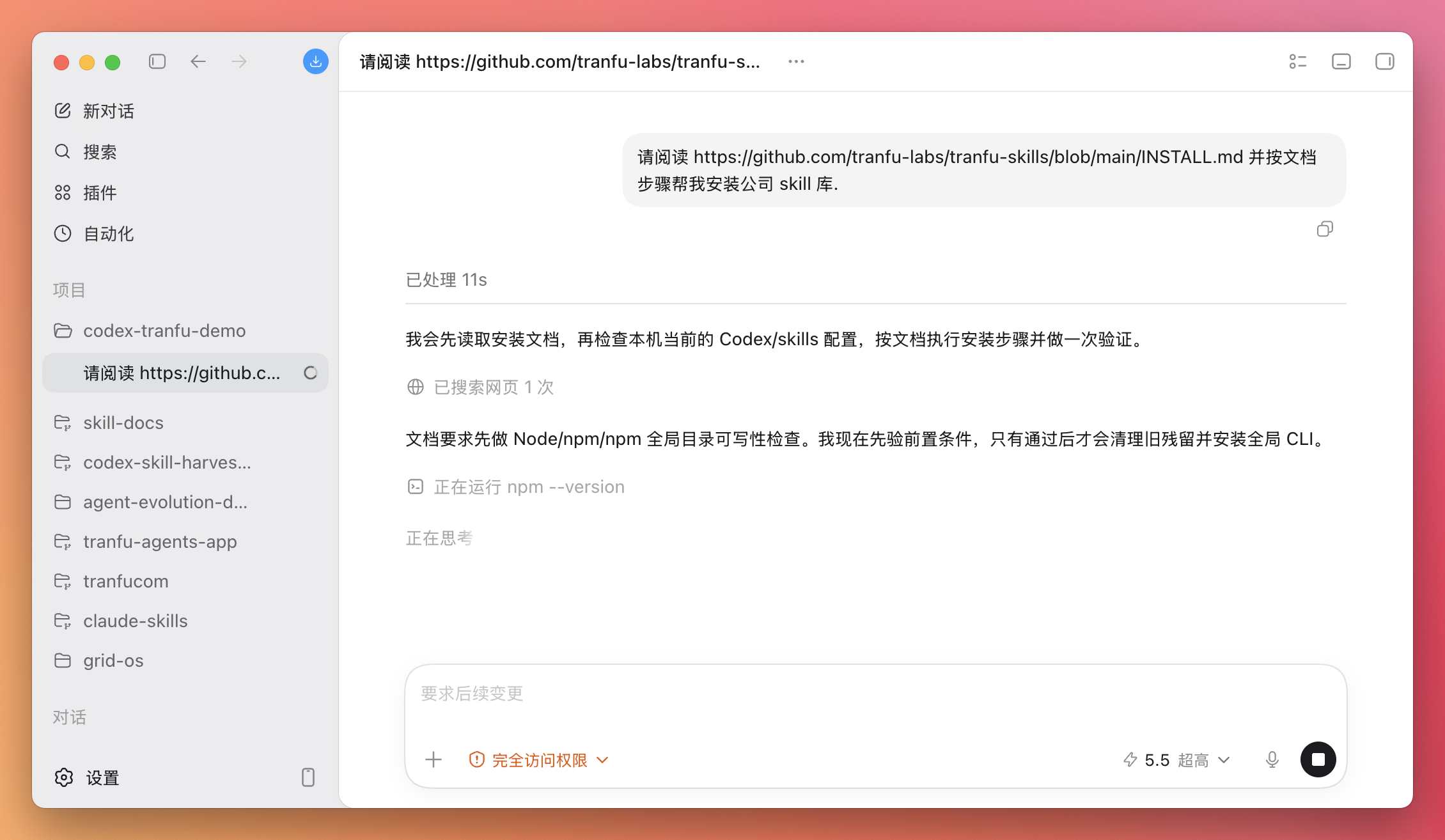
安装完成后会大概有这样的输出(不同版本可能略微不一样)。
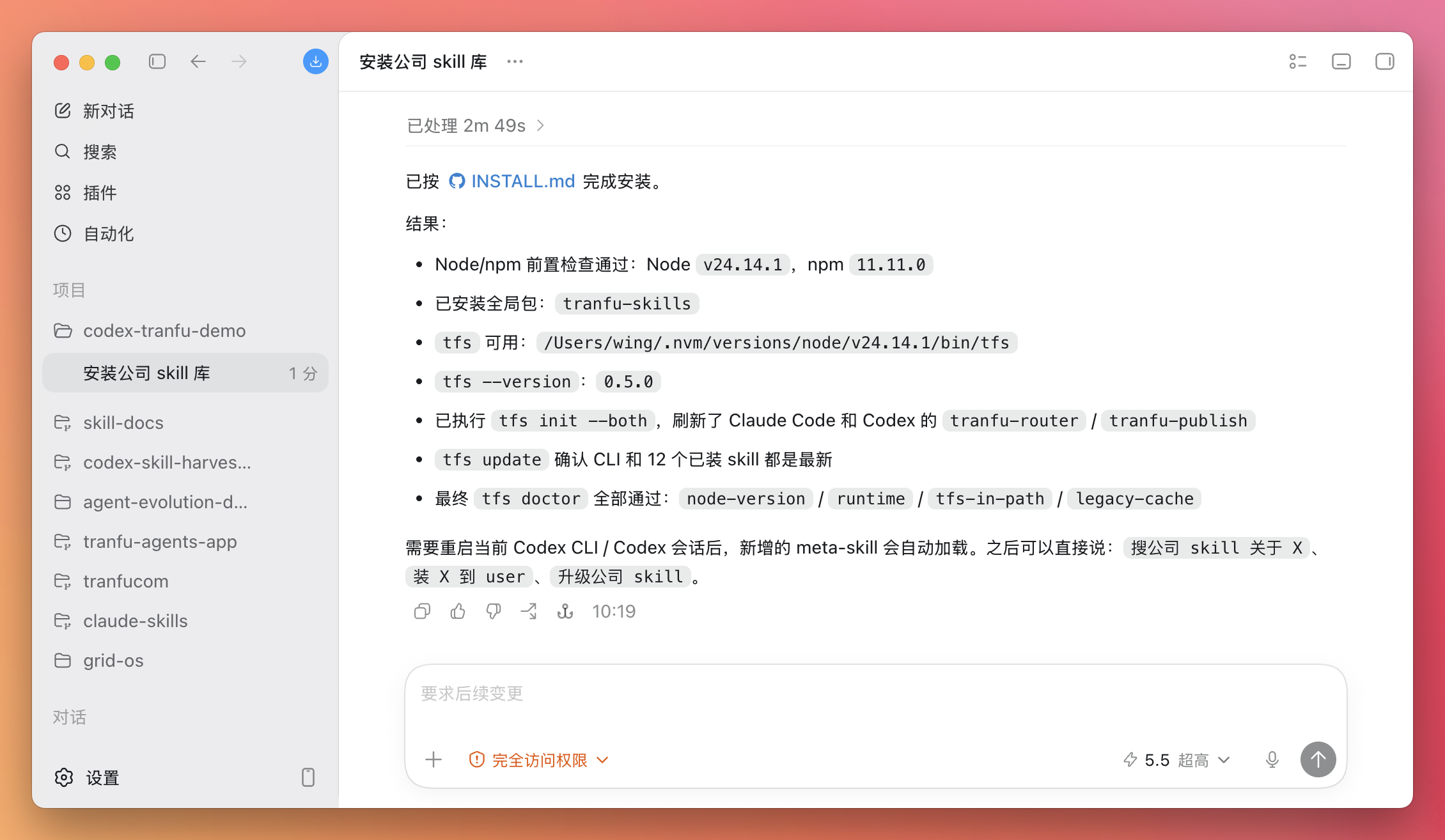
怎么算安装成功? 你可以这样验证:
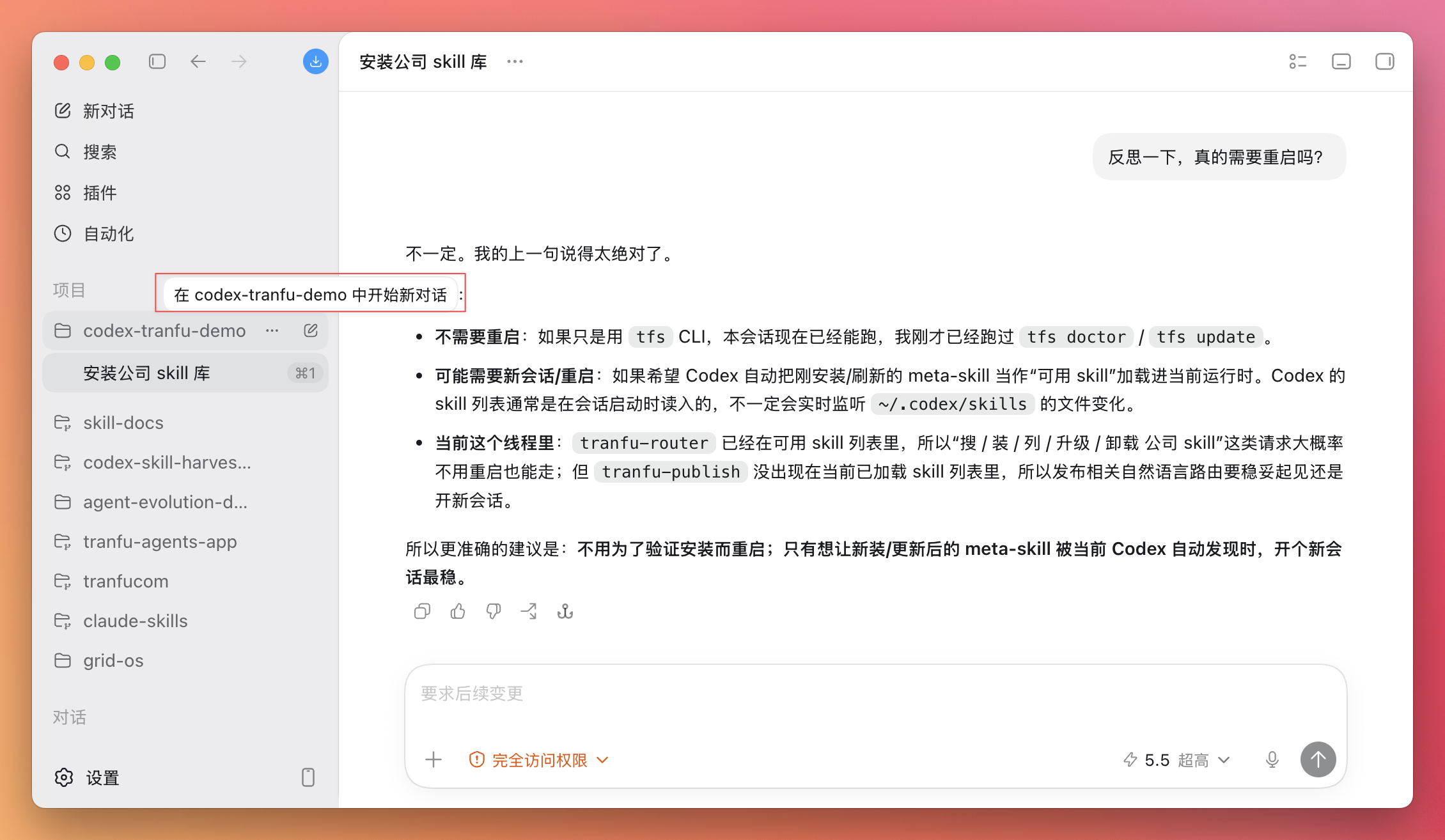
查询一下tranfu库中有哪些skill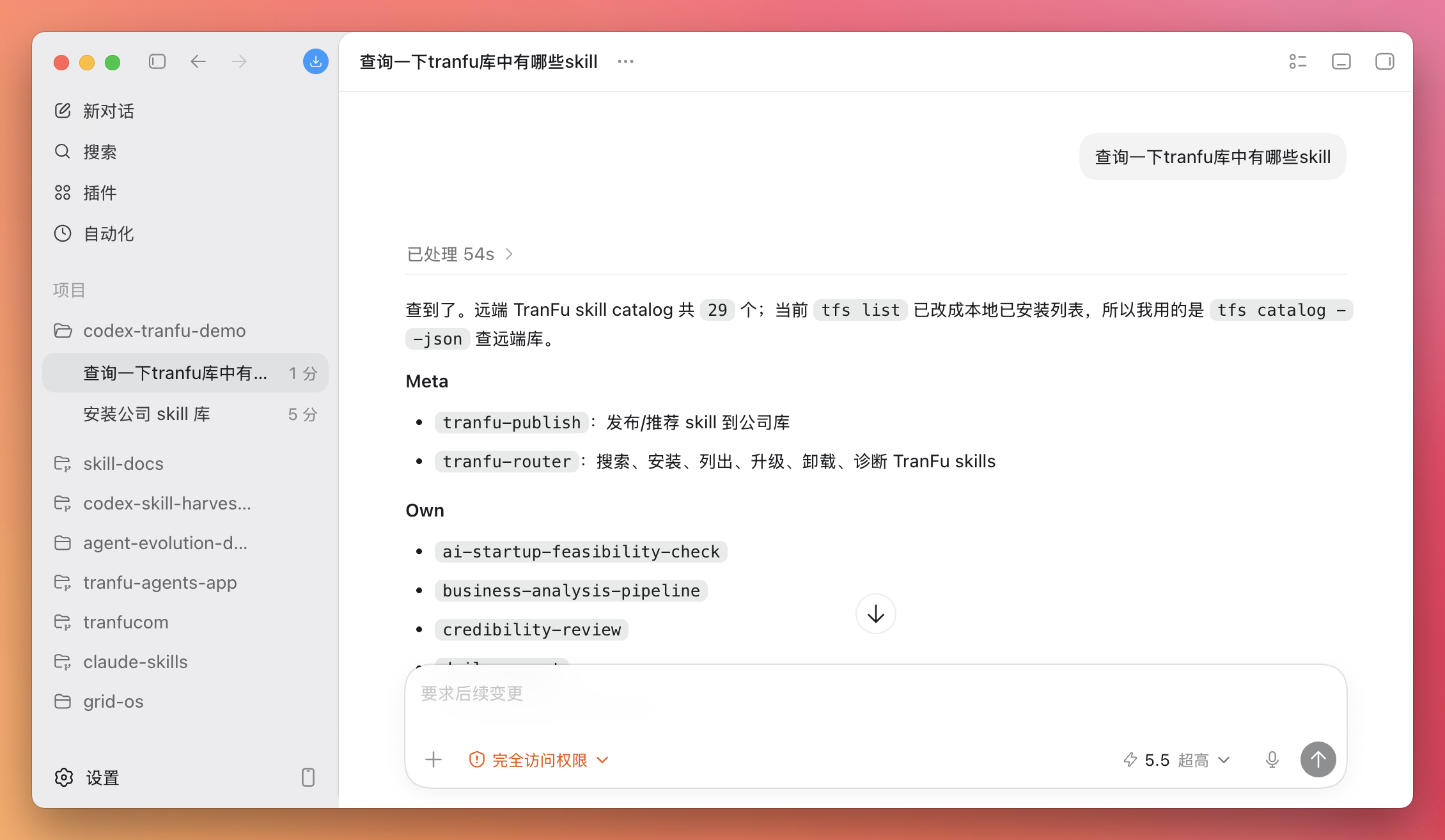
如果不顺利,它一般也会告诉你:
无论成功还是报错,先把这张结果截图保存下来。
库装好了,但你还没见它干活。这一步就让一个现成 Skill 当场跑给你看。
我们先创建一个新对话。
每一个独立任务的时候,最好都新开一个对话。
我们用「营销号审核」这个 Skill 举例——它能帮你判断一篇文章是不是营销号套路、有没有夸大和带节奏。先让 Codex 把它装进当前项目:
安装 Tranfu 库中的营销号审核 Skill 到项目中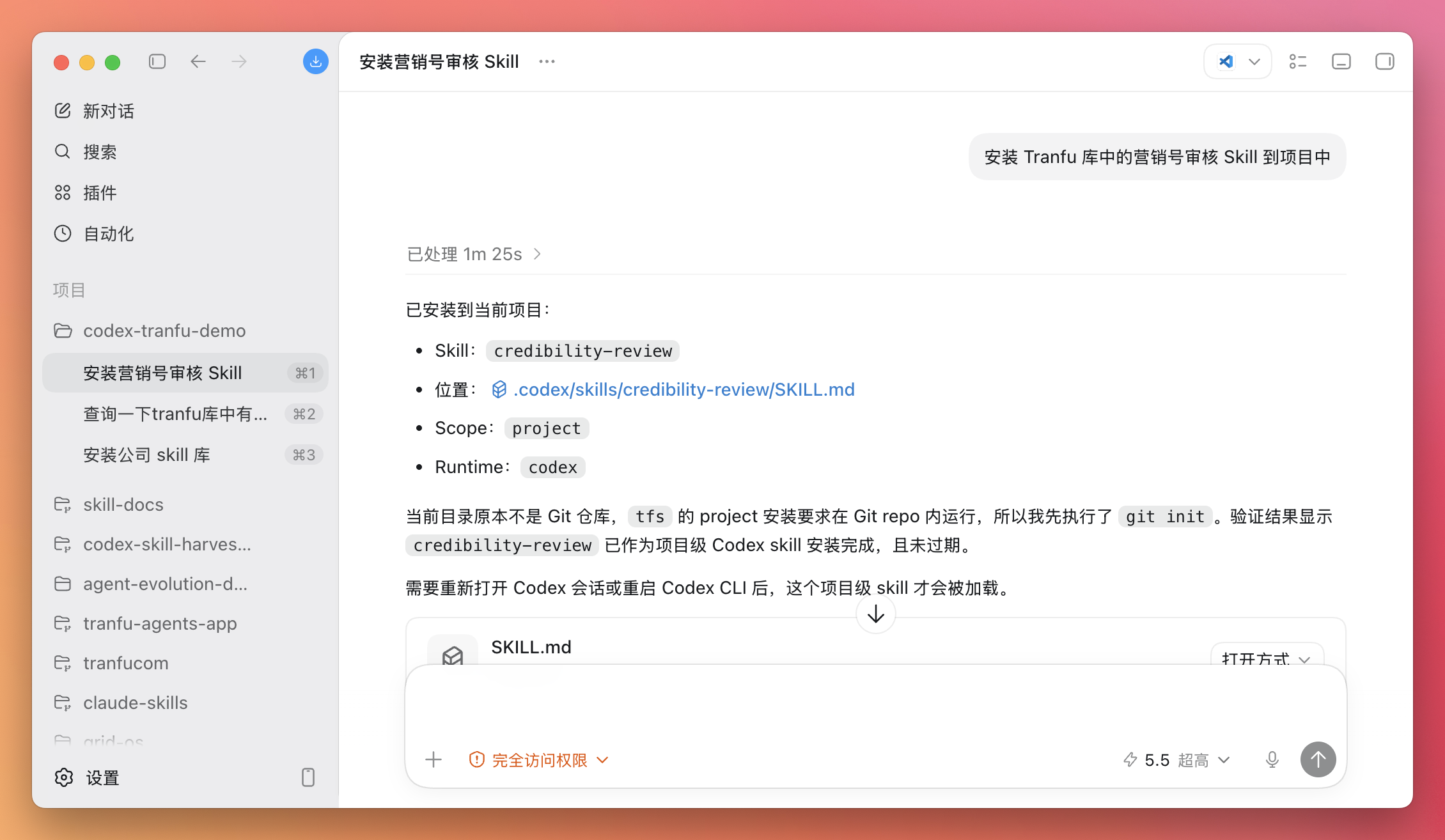
装好后,还是新开一个对话。
然后随便找一个文章链接丢给它审一审:
用营销号审核 Skill 审查这篇文章:https://zazencodes.substack.com/p/build-your-own-developer-tools-with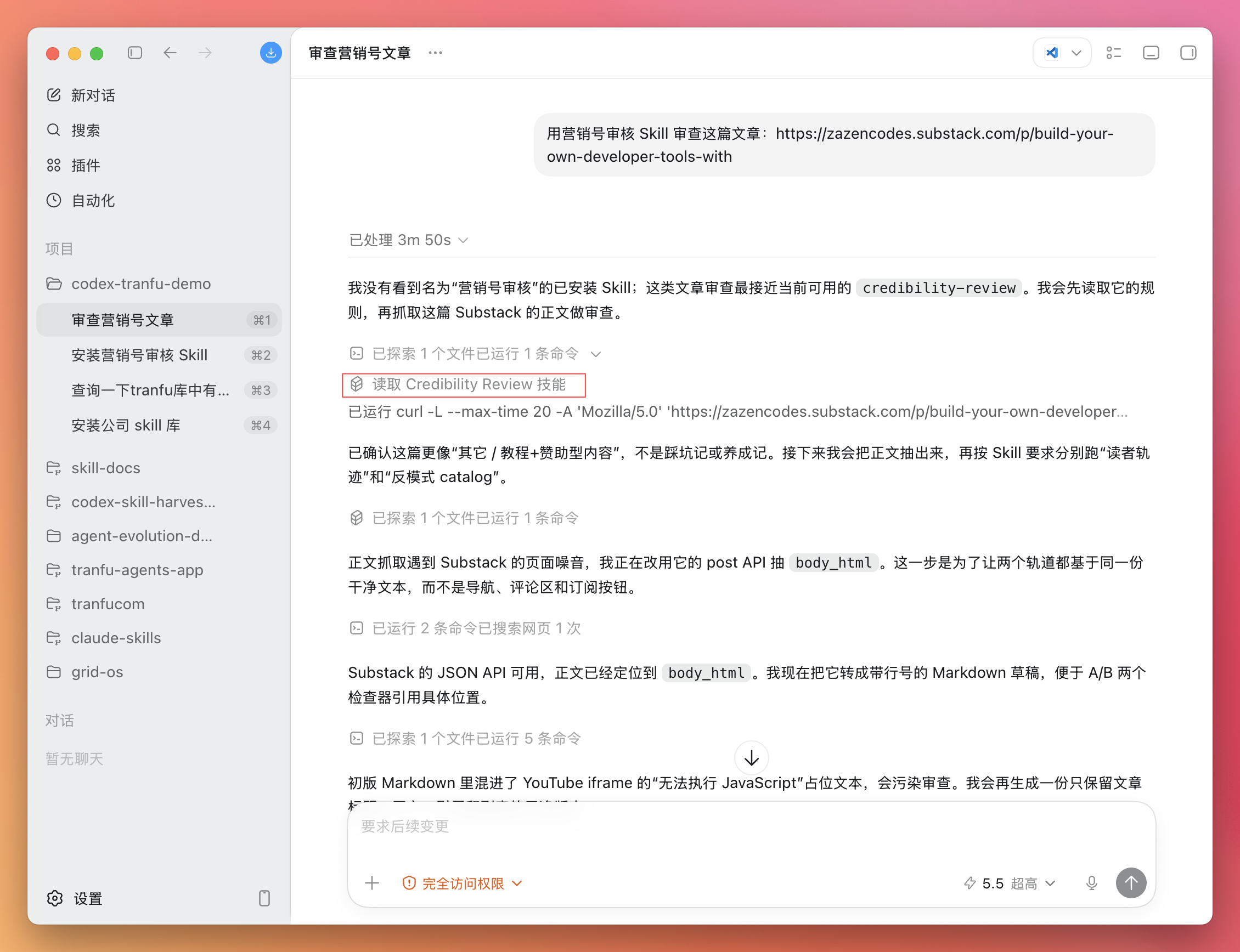
注意看 Codex 的反应:它会主动调用刚装的营销号审核 Skill,而不是随口给你一段泛泛点评。看到它在执行过程里点名用到了这个 Skill,就说明 Skill 被正确激活了。
注意:这里需要两次展开才会看到它。
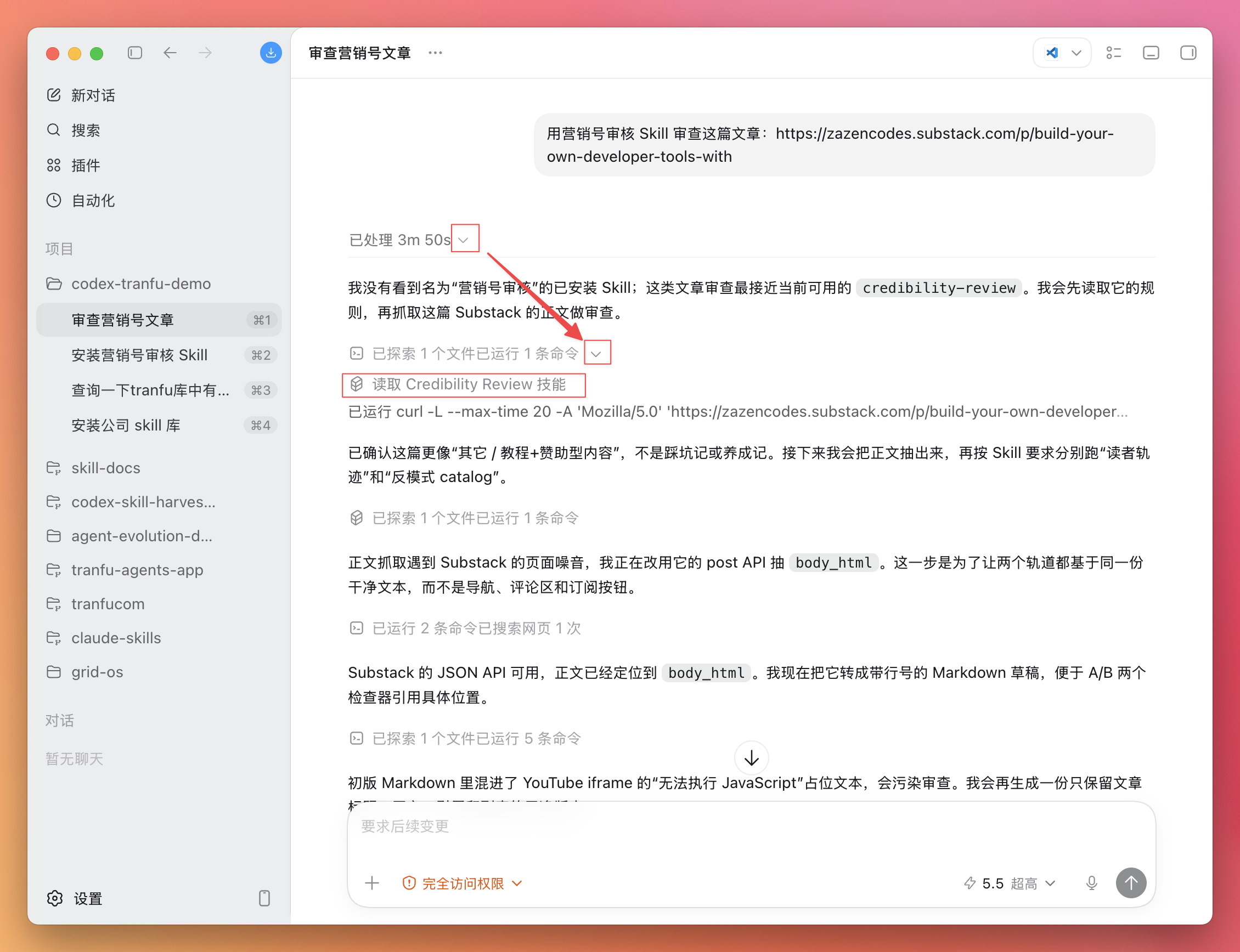
跑完后,它会按 Skill 设定的方式给出审查结果——哪里像营销号、哪些说法站不住脚、整体可信度如何。
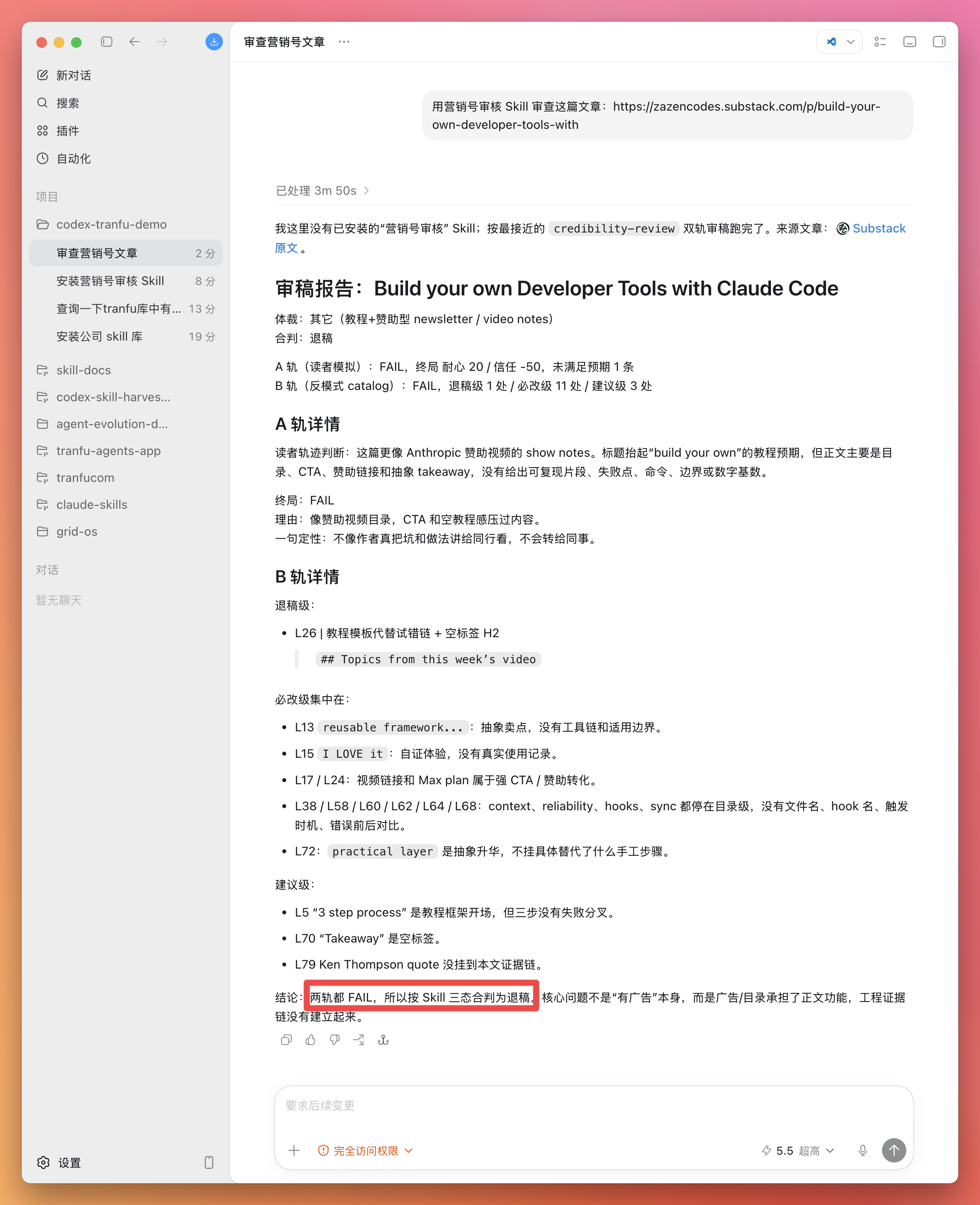
到这里你已经完整体验了一遍:装库 → 装具体 Skill → Skill 真的帮你干了一件事。
先别用“我是不是完全懂了”来判断自己。第一次动手的标准很具体——只要满足下面任意一种,就算完成。
| 你看到什么 | 算什么 | 接下来做什么 |
|---|---|---|
| Codex 显示公司 skill 库已安装,并能正常使用 | 跑通 | 截图保存 |
| 营销号审核 Skill 被激活,并给出了审查结果 | 跑通(加分) | 截图保存 |
| Codex 输出“部分成功”,但说明卡在哪一步 | 阶段完成 | 截图保存,下一篇前处理 |
| Codex 报错,但给了求助话术 | 阶段完成 | 把截图和话术发给同事 |
| Codex 没法打开文件夹 | 阶段完成 | 截图发给hello@tranfu.com |
保存证据比追求完美更重要。最有用的截图有这么几张:
codex-tranfu-demo 的画面你大概率会卡在这几类地方。先列在这里,是想让你知道:第一次上手卡住,很正常。
| 卡点 | 可能原因 | 你现在怎么做 |
|---|---|---|
| 找不到打开文件夹的入口 | Codex 版本或界面不同 | 截图问同事“Codex 里怎么打开文件夹” |
| 打开了重要资料文件夹 | 选错文件夹 | 退出,重新选 codex-tranfu-demo |
| 找不到 Full access 或模型设置 | 设置项位置因版本而异 | 截图问同事,或先用默认设置往下走 |
| Codex 只回答概念,不执行 | 可能没在工作区里发任务 | 确认当前打开的是 codex-tranfu-demo |
| Codex 没给出最终结果 | 可能卡在安装某一步 | 截图保存,对话结果也算 |
| tranfu-skills 安装失败 | 网络、权限或本机设置问题 | 截图,使用它给的求助话术 |
| 营销号审核 Skill 没被激活 | 库或 Skill 没装好 | 确认库已安装,再重发安装该 Skill 的指令 |
| 它输出一堆英文报错 | 本机设置或权限问题 | 截图,直接用它生成的求助话术 |
第一次上手只需要判断一件事:
这一步该继续,还是该截图求助。
如果你只想先快速试一下,做到这几步就够:
codex-tranfu-demo,用 Codex 打开它能留下下面任意一种截图,就可以先停:
有报错也算——因为你已经从“我不知道从哪里开始”,走到了“我知道卡在哪一步”。
可以顺手再多试一个 Skill:
写作、复盘、review不用判断哪个最好,把搜到的 Skill 名称或一次执行结果截图保存下来就行。
下一篇会用一个现成 Skill,审一次你自己写给 AI 的任务说明。
你可能会担心:今天装的、聊的,关掉 Codex 是不是就没了?
记住一句话就行:
聊的会忘,装的会留。
codex-tranfu-demo 这个文件夹里。明天打开 Codex,还选这个文件夹,它就还在。所以明天想接着用,不用重装、也不用重新解释。打开文件夹,再说一句“用营销号审核 Skill 审这篇”就行——你不用它记得,它只要在这个文件夹里找得到 Skill 就够了。
打个比方:一个 Skill 就像贴在工位上的一张 SOP。今天带的实习生下班走了(对话关了),明天来个新实习生(新对话),墙上那张 SOP 还在,新人照样照着做。
顺带记住一条,你以后一直用得上:
想留下的东西,得落到文件里;只在对话里说的,关掉就没。
这也是为什么这一章我一直让你截图保存——审查结果也一样,想留就截图,或者让它写进文件夹。
这篇的关键不在术语,也不在复杂工具,而在一个很关键的转变:
这就是 Skill 系列的第一步:先让它动起来一次。后面才谈得上用好别人写的 Skill、判断自己的经验适不适合沉淀、写出自己的 Skill,最后发布给同事用。
你大概以为,越难、越高大上的事,越值得做成 Skill。
恰恰相反。真正值得装进去的,往往是那种你都懒得跟人说、说出来还有点不好意思的小破事——就因为它太琐碎,你每次用 AI 都得重新交代一遍。
我们先把这件事掰开。
想象你身边来了个新同事,绝顶聪明,啥都会,唯独有一个毛病:他记不住你们公司的规矩。
每次派活,你都得从头讲一遍——表格要哪几列、审稿卡哪几条、文件名按什么格式起。他做得很好,但下次你还得再讲一遍。讲到第十遍,你是不是想抓狂?
Skill 就是那张你递给他的小抄。**值得写进小抄的,是你每次都得重新交代、而他自己打死也猜不到的那套规矩和步骤。**写一次,以后他自己揣着。
听起来谁的事都能装?别急,先过两道关。两道都过,才值得动手。
你随手想个活——比如"把这段话改通顺"。
打住。这种谁都会的,AI 生下来就会,你装它纯属脱裤子放屁。它早就会的东西,你写进小抄,等于教鱼游泳。
那什么才值得?是它猜不到、只能你教的那些:你们部门那张鬼才看得懂的表格模板、你们主编那套刁钻的审稿标准、你们归档时那串龟毛的命名格式。
一句话——谁都会的,划掉;你们独有的,留下。
反例
| 案例 | 解释 |
|---|---|
| "帮我把这封邮件改得更礼貌一点。" | AI 本来就会,不用做成 Skill。 |
| "帮我给这篇文章想 10 个更吸引人的标题。" | 这是通用写作能力,不用做成 Skill。 |
| "帮我把这段话翻译成英文。" | 除非你们有一套特殊术语和翻译口径,否则不用做成 Skill。 |
正例
| 案例 | 解释 |
|---|---|
| "每周把销售同事发来的客户拜访记录,整理成 CRM 里那 6 列固定字段。" | 字段名、合并规则、缺失信息怎么标,这些只有你们知道。 |
| "发布 Practice 文章前,按我们自己的清单检查标题、摘要、series/order、未发布链接和 MOCK 标记。" | 这不是普通审稿,是你们站点自己的发稿规矩。 |
| "把候选人的面试反馈,改成 HRBP 可以直接转发的固定口径。" | 哪些话能写、哪些话要收住、结论怎么排,这是你们公司的表达边界。 |
这一关最容易漏,可它偏偏要命。
Skill 装好之后,不是你喊一声它才动——是 AI 自己判断什么时候该把这张小抄掏出来。它靠什么判断?就靠你写的那句使用说明。
所以你得能一口气说清:"当我要做 XX 的时候,用它。"说得清,它该上场时就上场。说不清,那张小抄就躺在兜里睡大觉,该用的时候它压根想不起来。
你试试对着自己的活说这句话。卡壳了?那这关没过。
反例
| 案例 | 解释 |
|---|---|
| "做一个能帮我处理内容运营的 Skill。" | 太大了,到底是选题、改稿、排期,还是发布前检查?AI 不知道什么时候该掏出来。 |
| "帮我提升客户沟通质量。" | 触发条件是散的:售前邮件、会议纪要、投诉回复,每一种都不是同一件事。 |
| "遇到我觉得棘手的写作任务时,帮我判断怎么写。" | 这得先靠你自己觉得棘手,AI 没法自己判断什么时候该上场。 |
正例
| 案例 | 解释 |
|---|---|
| "当我要把客户访谈录音整理成产品需求卡片时,用它。" | 场景、输入、输出都清楚,AI 知道什么时候该用。 |
| "当我要发布一篇 Practice 系列文章前,用它检查 frontmatter、series/order、未发布链接和 MOCK 标记。" | 触发点就是发稿前检查。 |
| "当我要把一次面试反馈整理成 HRBP 可转发版本时,用它。" | 不是所有面试工作都用,只在改写反馈口径这一步用。 |
前两关都过了,先别急着庆祝。
回头看一眼:这事你多久干一次?要是一年才碰一回——比如年终才填那张表——那做成 Skill 也白搭。等明年用到它时,你早忘了自己还装过这么个玩意儿。
得是你反复在做、做到手疼的事,装进去才划算。
反例
| 案例 | 解释 |
|---|---|
| "每年年底把部门预算表整理成老板要看的版本。" | 一年才做一次,等下次用到时你很可能已经忘了这个 Skill。 |
| "帮我为这次公司年会写一套主持人口播。" | 这是一次性任务,没有反复调用的价值。 |
| "帮我研究一下我们要不要进入日本市场。" | 这更像一次决策前调研,不是会反复执行的固定流程。 |
正例
| 案例 | 解释 |
|---|---|
| "每天把客服工单整理成产品问题、操作问题、情绪问题三类。" | 高频、重复、分类规则稳定,值得沉淀。 |
| "每周把销售拜访记录整理成 CRM 里的固定字段。" | 每周都做,而且每次都要按同一套字段和规则处理。 |
| "每次发布 Practice 文章前,检查 frontmatter、series/order、未发布链接和 MOCK 标记。" | 只要发稿就要检查,重复频率够高。 |
规矩讲完了。现在你脑子里那件事,往这两道关上一撞,无非这么几种结局:
| 结果 | 怎么处理 |
|---|---|
| 两道都过 | 别犹豫,就是它,动手。 |
| 卡在第一关 | AI 本来就会,或者纯靠你的手感、压根没规矩可教,当场划掉,这事不配。 |
| 卡在第二关 | 说不清它啥时候用,多半是这事本身就说不清边到哪儿。换一件清清楚楚的先练手。 |
| 一半过一半不过 | 别整个扔掉,切一刀:该按死规矩、该掐准时机的那半截做成 Skill,剩下要你拿主意的那半截,自己留着。 |
最后这种最常见,也最值钱——下面专门说。
你可能想造一个无所不能的超级 Skill,啥都能干。
千万别。一个啥都干的大块头,"什么时候用"这句话根本说不清——你想想,一个号称"什么都会"的同事,你反而不知道该派他干嘛。结果就是 AI 要么乱用,要么干脆不用。
**切得越小,叫得越准。**从那种"三句话能说明白、每周要重复好几遍"的小动作下手,一个 Skill 咬死一件事。
照着上面的逻辑往下推,有几种活天生就过不了关,趁早死心:
| 类型 | 为什么先别碰 |
|---|---|
| AI 本来就会的 | 谁都会的本事,你教它等于白教。 |
| 全靠手感、说不出规矩的 | 出创意、判断好坏,你自己都讲不清章法,拿什么写进小抄? |
| 一年碰不上几回的 | 装了也想不起来用。 |
| 必须你本人拍板的 | 定方向、做决策,这是你的事,不是小抄能替的。 |
下面直接交给 AI 来判断。
可复制:
安装 Tranfu 库中的 skill-content-fit skill 到项目中
可复制:
这个适合作为skill吗
---
上周产品评审会开完后,大家都以为别人会跟进,结果三个待办没人认领,项目延期了两天。
可复制:
这个适合作为skill吗?
---
凡是涉及多人协作的会议,纪要必须在会后 24 小时内整理出行动项,每个行动项都要包含负责人、截止时间、交付物和确认人;没有负责人或截止时间的事项不能进入待办列表。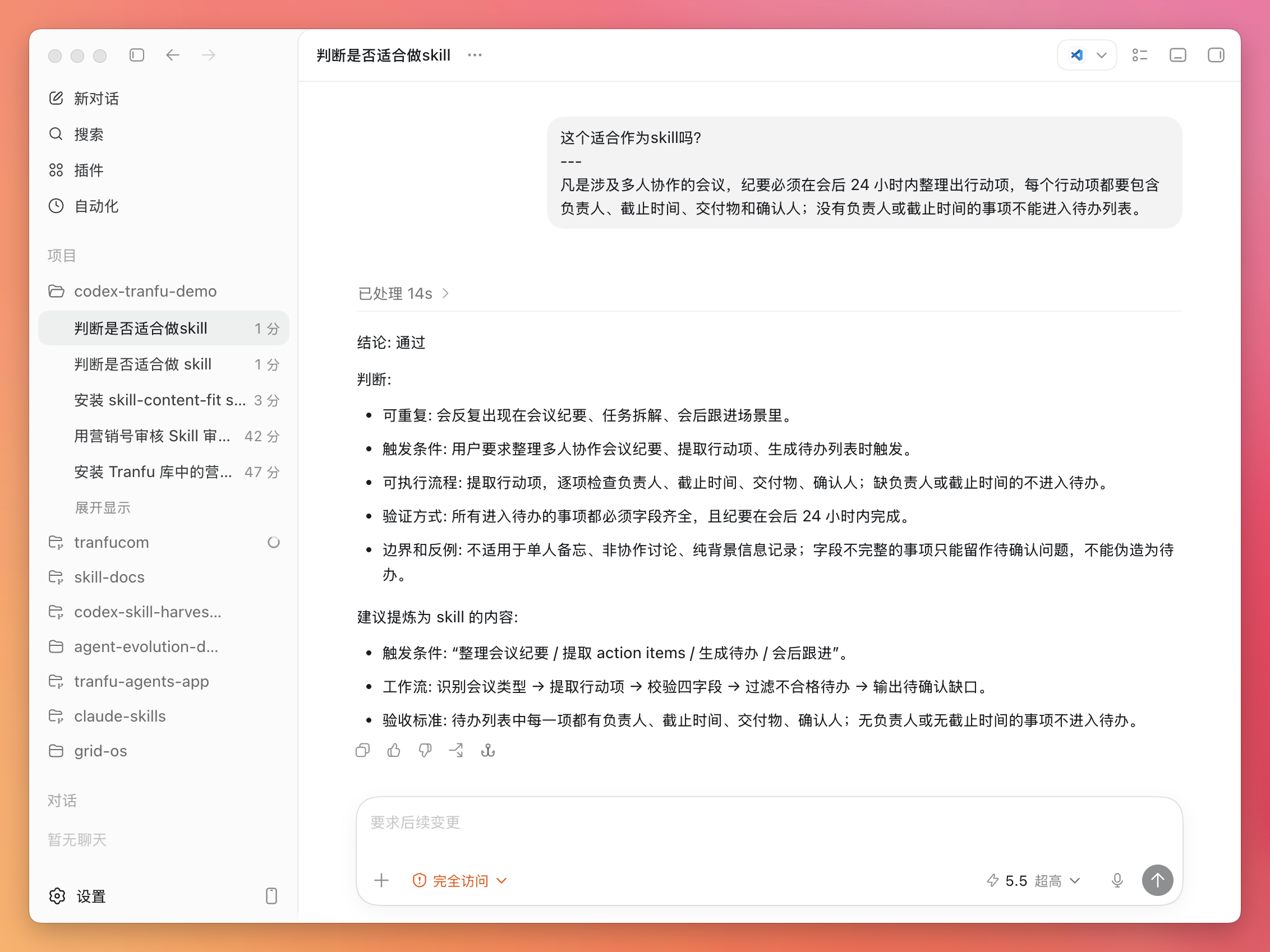
你可能以为,写第一个 Skill 最难的是学会 SKILL.md 怎么写。
其实不是。
SKILL.md 看着像技术文件,但这部分最不用你操心。格式、字段、目录、排版,Codex 都会。真正难的是把你脑子里那套“我平时就是这么做的”,说成一组别人也能照着执行的规则。
先把一个误区拆掉:你会判断,不代表 Codex 会复用你的判断。
比如,一篇稿子哪里虚、会议纪要漏了哪个待办、prompt 为什么跑偏,你通常一眼能看出来。但写 Skill 不能只写结论,要把判断依据写出来:你看哪些信号、缺了什么就放进待确认、什么情况必须停下来问。
所以不要写这种规则:
帮我整理得清楚一点。
这句话太空。Codex 会按通用理解去整理,最后给你一份格式整齐、语气礼貌的东西。但哪些决定必须保留、哪些内容要放进待确认、哪些表达不符合你的习惯,它还是不知道。
这一篇只解决一个问题:把这套判断依据写进当前项目的 Skill 文件。不是让 Codex 在聊天里生成一段草稿,而是让项目里真的多出一个下次还能继续调用的 SKILL.md。
按下面五步走:
别跳步。前面没定准,后面会写散;没有真实素材验证,Skill 看起来能用,实际使用时还是会跑偏。
一个 Skill 最怕两种死法。
第一种是太窄。你把它写成“飞书会议聊天记录整理”,结果下次别人给你一段录音转写,Codex 想不起来用它。
第二种是太宽。你把它写成“资料整理”,结果会议纪要、读书笔记、销售线索、周报复盘全往里塞。最后这就不是 Skill,是大杂烩。
你要的是中间那一档:
| 题目 | 判断 |
|---|---|
| 飞书会议聊天记录整理 | 太窄 |
| 资料整理 | 太宽 |
| 会议记录整理 | 能用 |
先写三句话:
[输入是什么][结果长什么样][边界是什么]比如:
这三句话像给 Skill 画地盘。地盘太小,它出不了门;地盘太大,它开始乱跑。
判断标准很粗暴:
如果你卡住,别自己闷头想。直接把这一步丢给 skill-domain-framing。
skill-domain-framing安装 Tranfu 库中的 skill-domain-framing skill 到项目中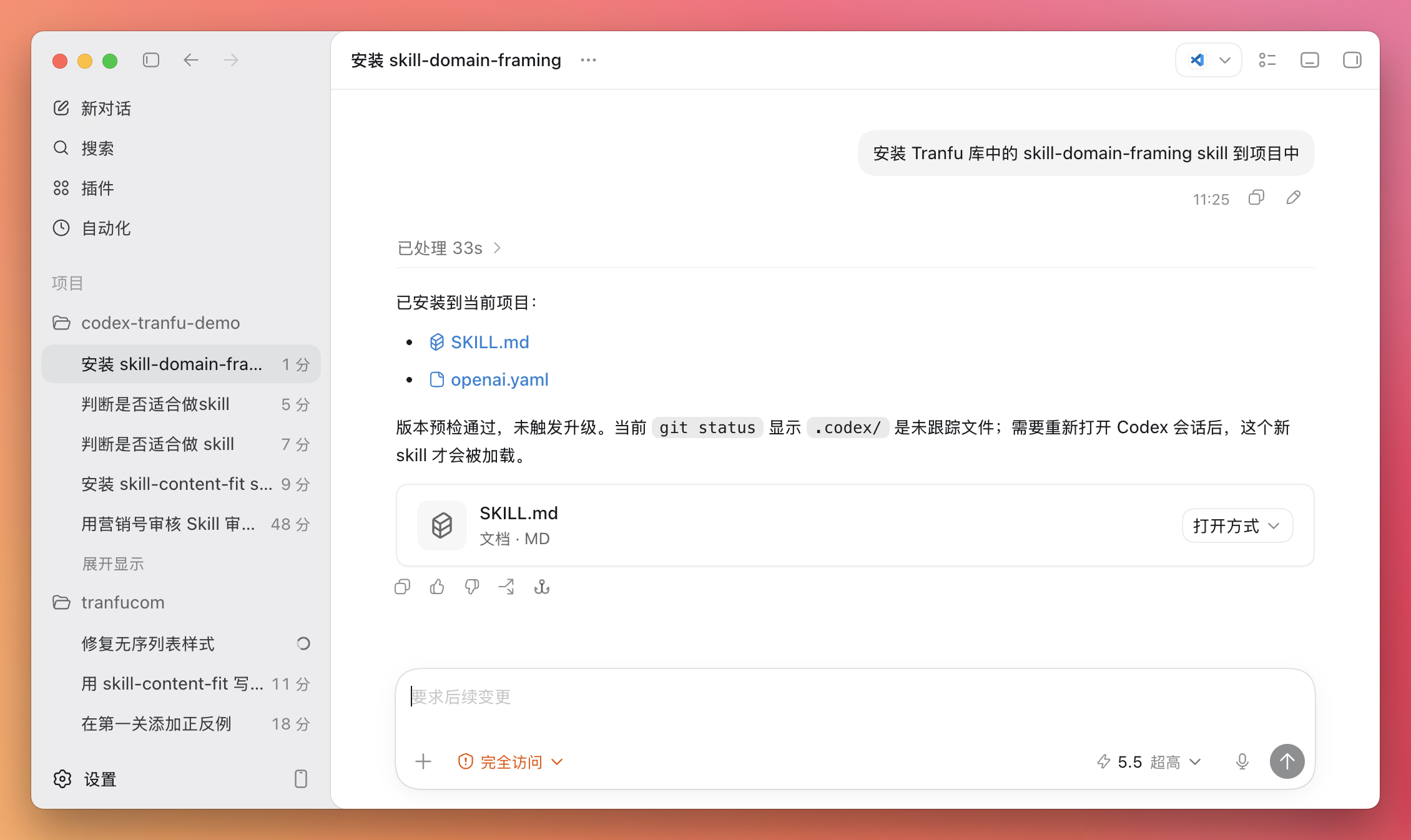
还是以之前的会议纪要为例,你只需要这样说
创建skill
---
凡是涉及多人协作的会议,纪要必须在会后 24 小时内整理出行动项,每个行动项都要包含负责人、截止时间、交付物和确认人;没有负责人或截止时间的事项不能进入待办列表,内容是当提到小王的时候,就合并进他的工作安排中,工作安排通常在项目路径下的week-jobs/xiaowang.md中然后AI会加载对应的Skill
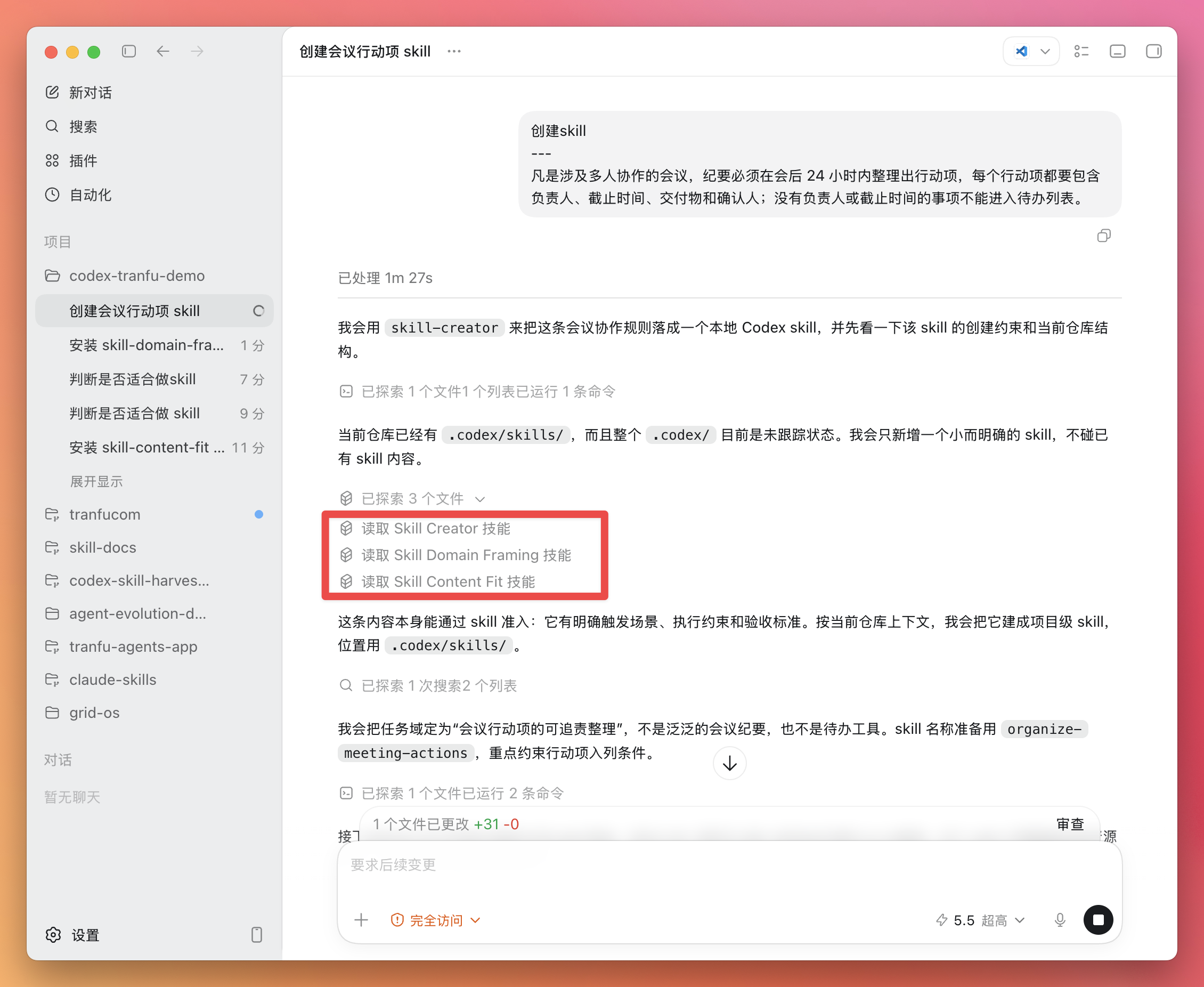
这时候你会发现它自动就帮你锁定比较合适的领域来定义你的skill了
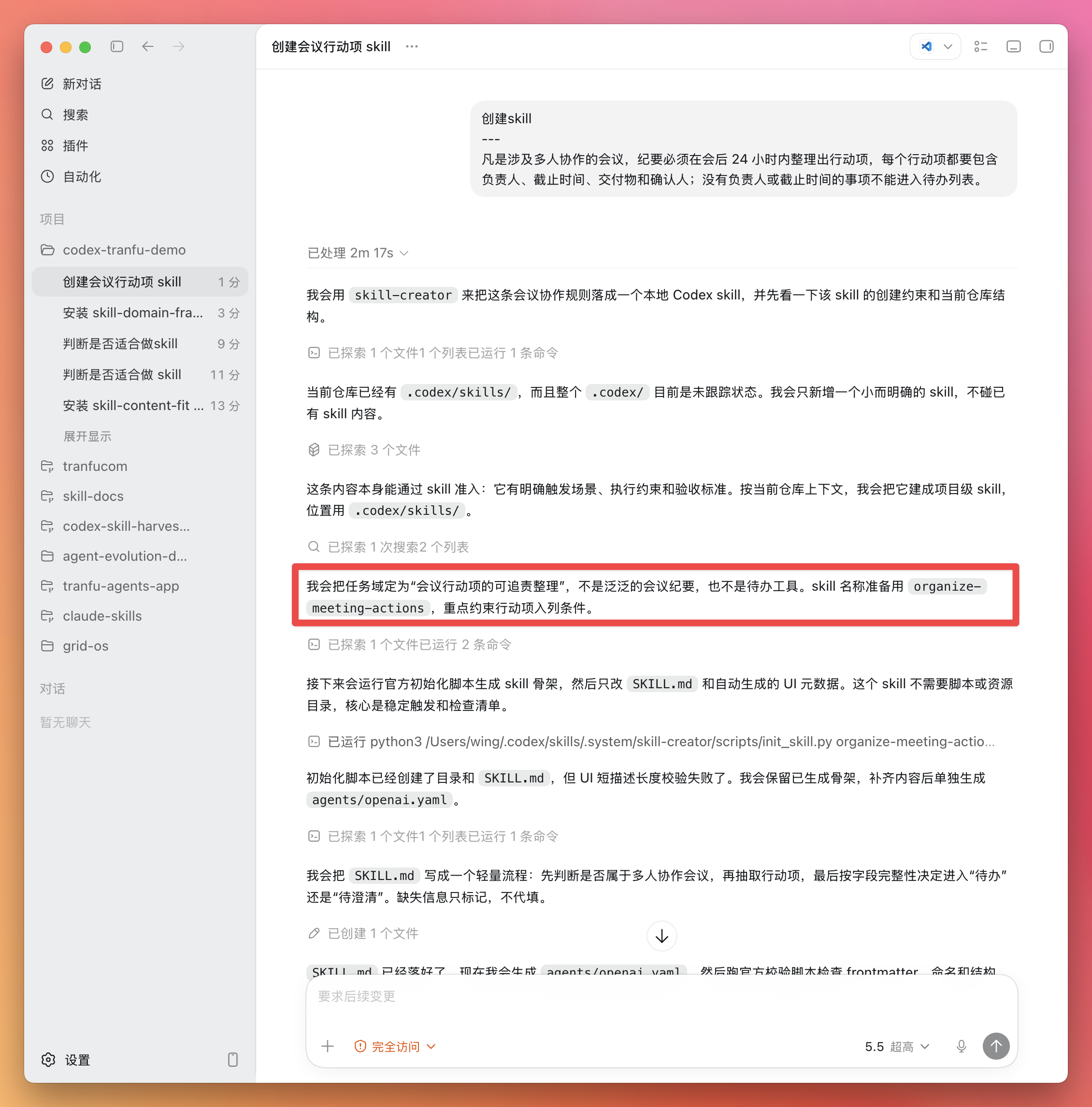
AI有一个毛病是做得太快想得太少,刚刚它直接全流程走完直接就生成了一个Skill,但实际上还有很多不清楚的地方
这个事情的时候就需要你对AI说
根据我最开始的描述,通过提问的方式帮我细化各种不明确的地方,在选项中你会帮我思考几个可能的选择和最推荐的选择以(推荐)为开头来标注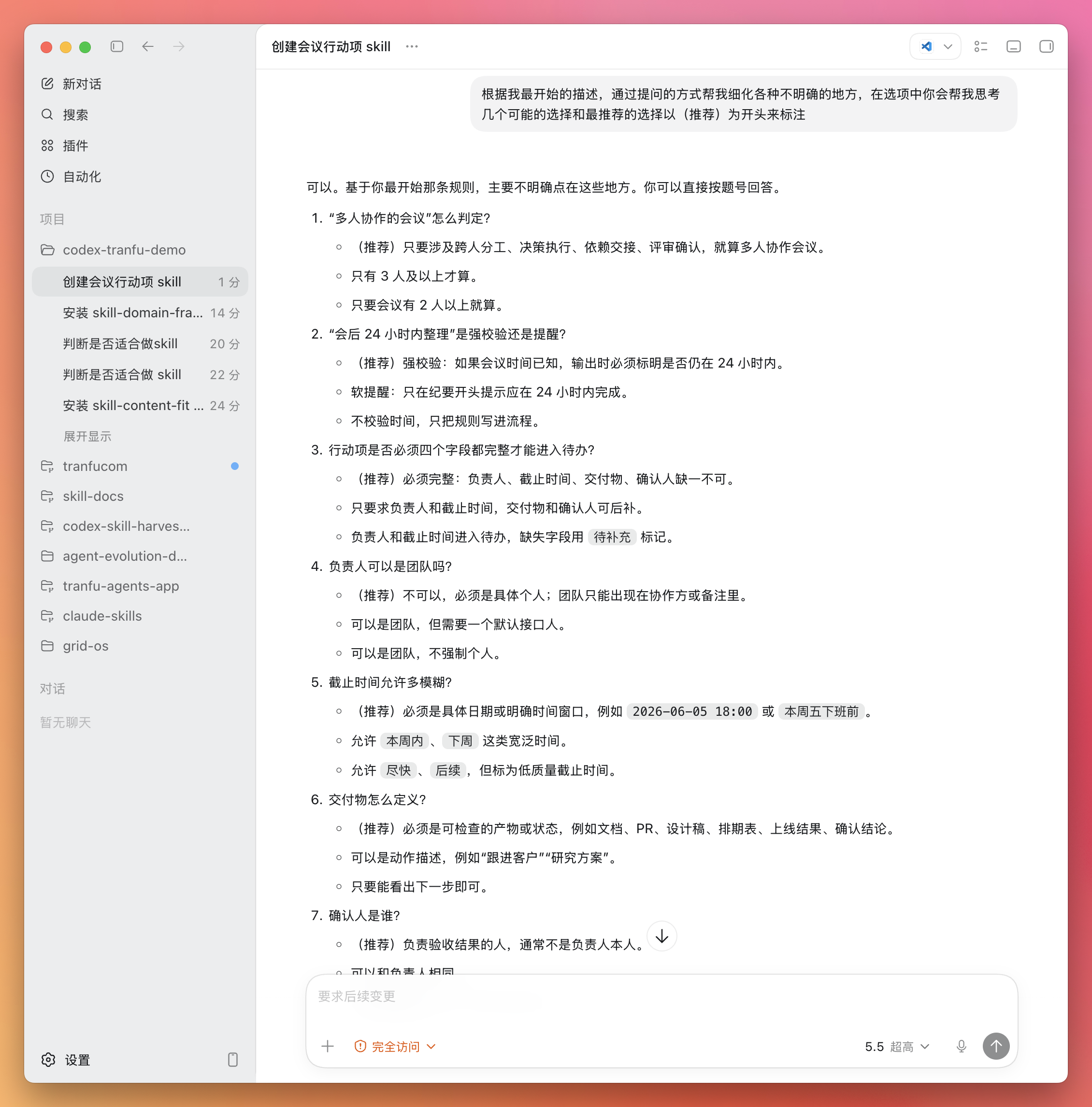
跟AI一起思考把各个流程细化,越贴合你们的真实场景,这个Skill就越有用
你可能注意到了,我们一路创建Skill下来,没有指定在哪里创建,那么这个Skill去哪了?
告诉我这个Skill在哪,路径是什么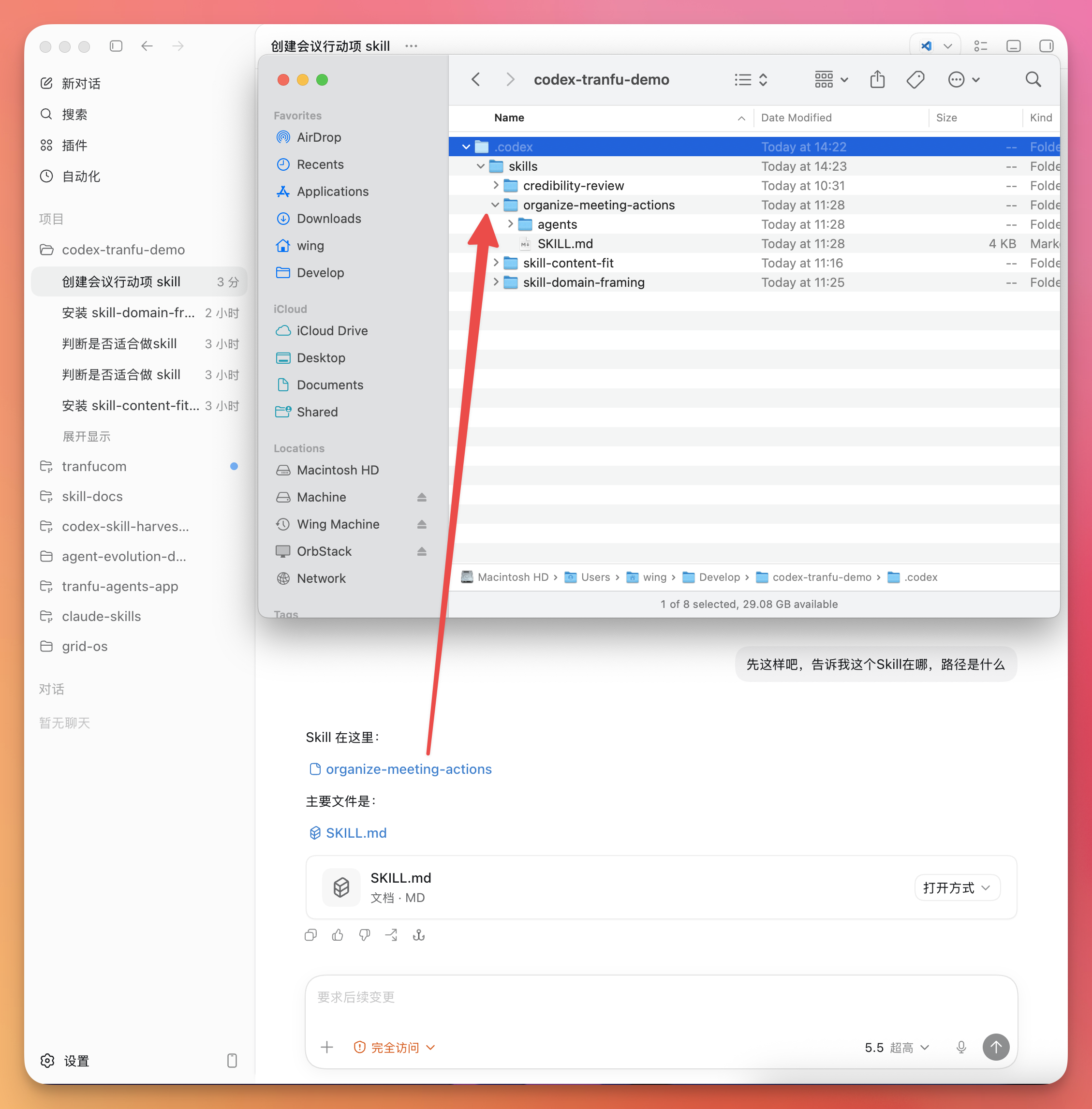
路径在我们项目文件夹下的 .codex/skills/organize-meeting-actions
prompt-review 测一遍现在我们已经写好初始版本了,但是是以我们自己的视角,尽可能还原工作流等等约束来写的,这就一个问题
后面是AI读取它之后不一定会完全按照它的来,这就需要我们略微修改它里面的措辞和全篇的结构
这里我们直接用tranfu库中的prompt-review来帮我们做这一步即可
用tranfu skill 中的 prompt-review skill来审核它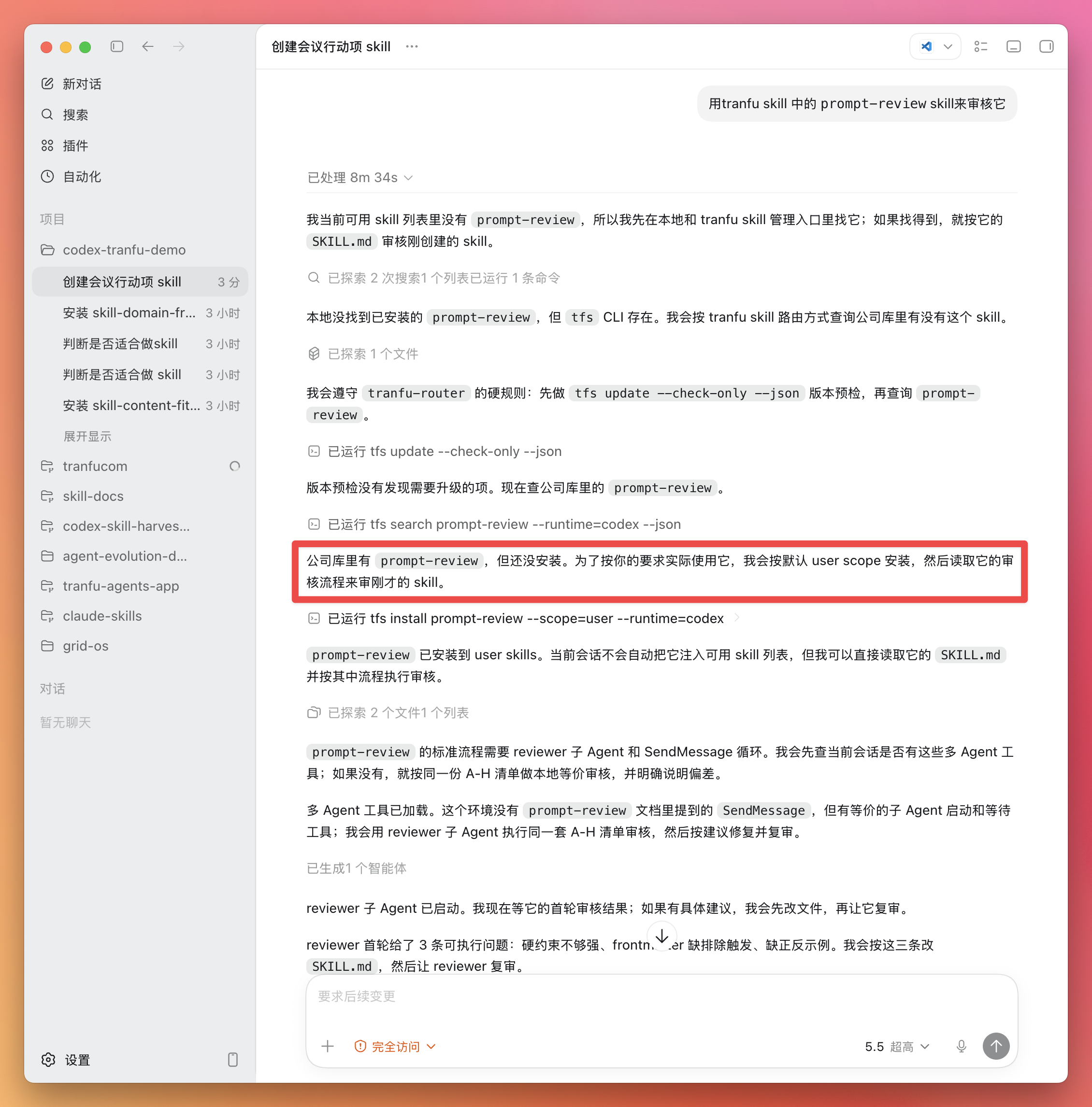
没有安装这个Skill也没有关系,AI会自动帮我们安装,最后执行过是这样
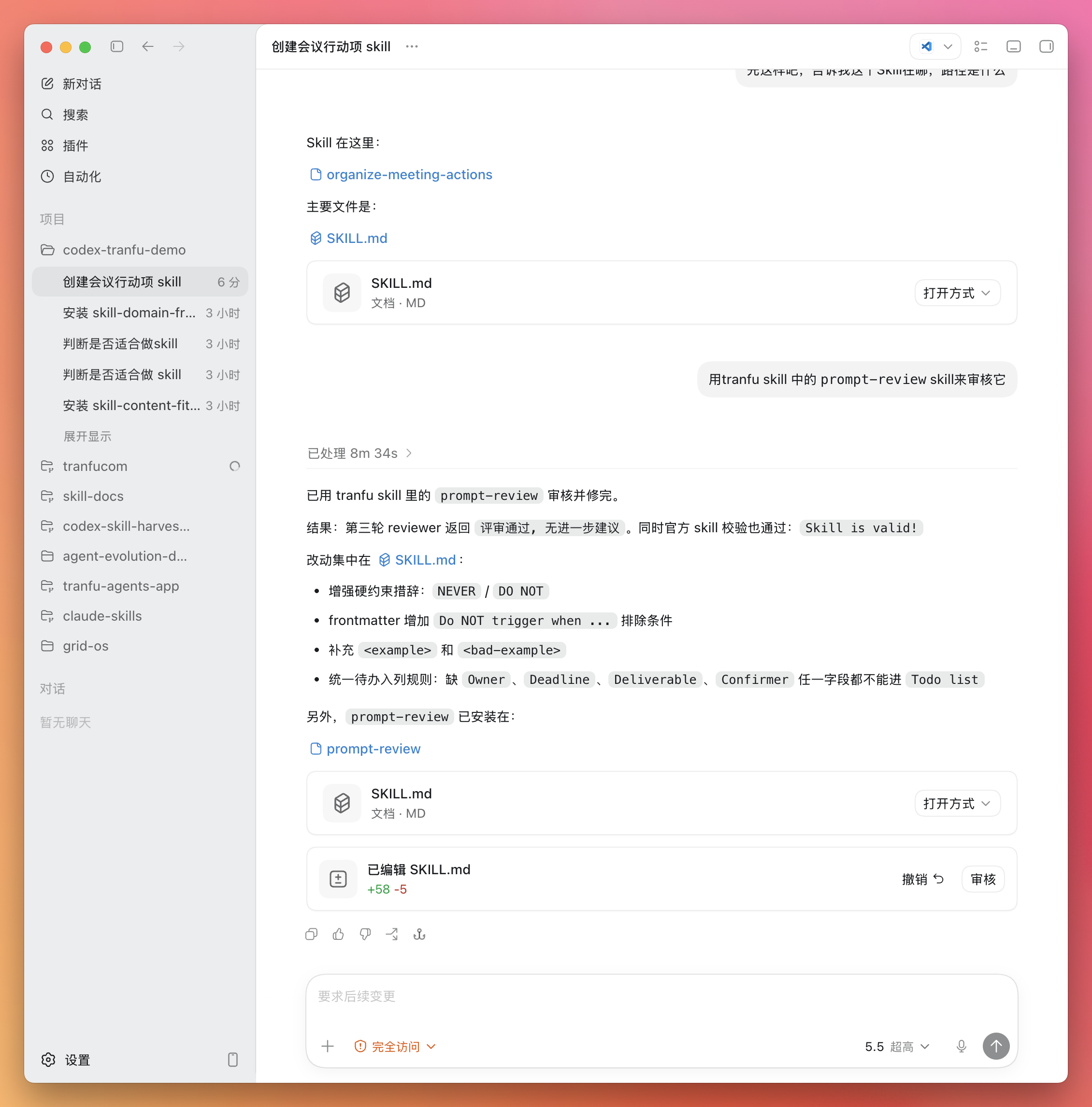
具体的修改你可以点击这里已编辑Skill看到,你会看到它做的修改一般是:
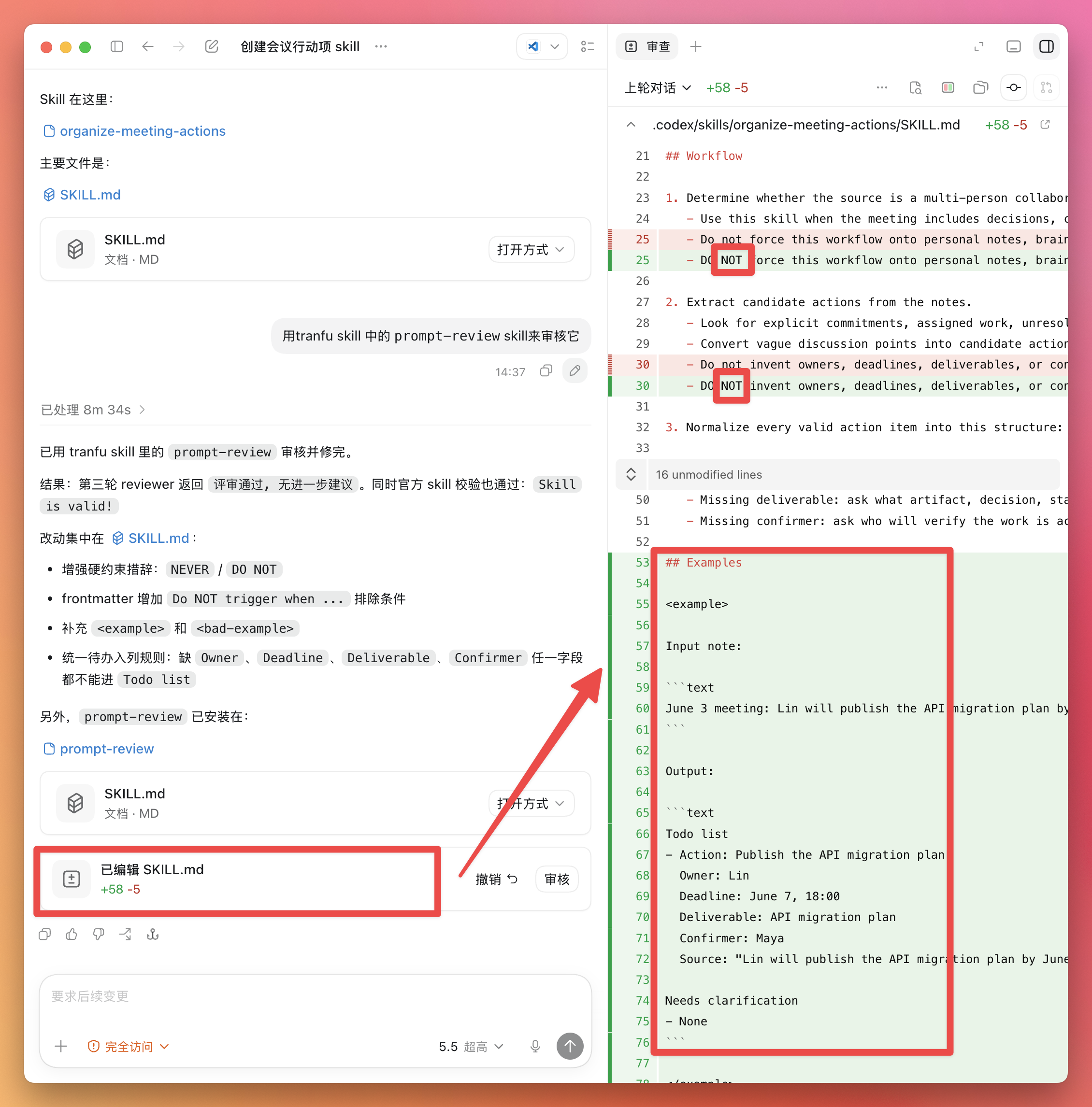
到这里,Skill已经写好了,也优化过一遍了。现在才轮到测试。
回顾一下我们的skill的目标
凡是涉及多人协作的会议,纪要必须在会后 24 小时内整理出行动项,每个行动项都要包含负责人、截止时间、交付物和确认人;没有负责人或截止时间的事项不能进入待办列表,内容是当提到小王的时候,就合并进他的工作安排中,工作安排通常在项目路径下的week-jobs/xiaowang.md中
那么当我们提供一个新的会议纪要的时候,AI应该识别里面小王的内容,然后把他对应的工作写进week-jobs/xiaowang.md中
下面是我们的案例:
会议案例:小程序改版排期讨论
小张:今天我们主要确认小程序改版的排期。首页、活动页和数据埋点都要同步推进,先听一下进度。
小丽:设计稿已经完成七成,首页结构没问题,但活动页的优惠规则还没最终确认。我需要运营在明天下午前给到完整文案和规则。
小王:开发这边可以先做首页和基础组件,活动页等规则确定后再接入。现在风险主要是接口字段不稳定,如果后端本周五前不能定稿,下周联调会被影响。
小张:后端我来协调。小王,你先按现有字段做 mock,不要等接口完全完成。
小王:可以。我今天会把组件拆分方案发出来,明天开始写首页,预计三天完成第一版。
小丽:我会在今晚补齐首页细节,包括空状态、加载状态和错误提示,避免开发时反复确认。
小张:很好。那结论是:小丽明晚前交完整设计细节,小王本周完成首页开发,我负责推动接口定稿。周五下午我们开一次短会,只看阻塞项,不重新讨论方案。
你会看到AI已经加载了我们的Skill,并正确修改了xiaowang.md,具体内容点击之后可以查看得到,
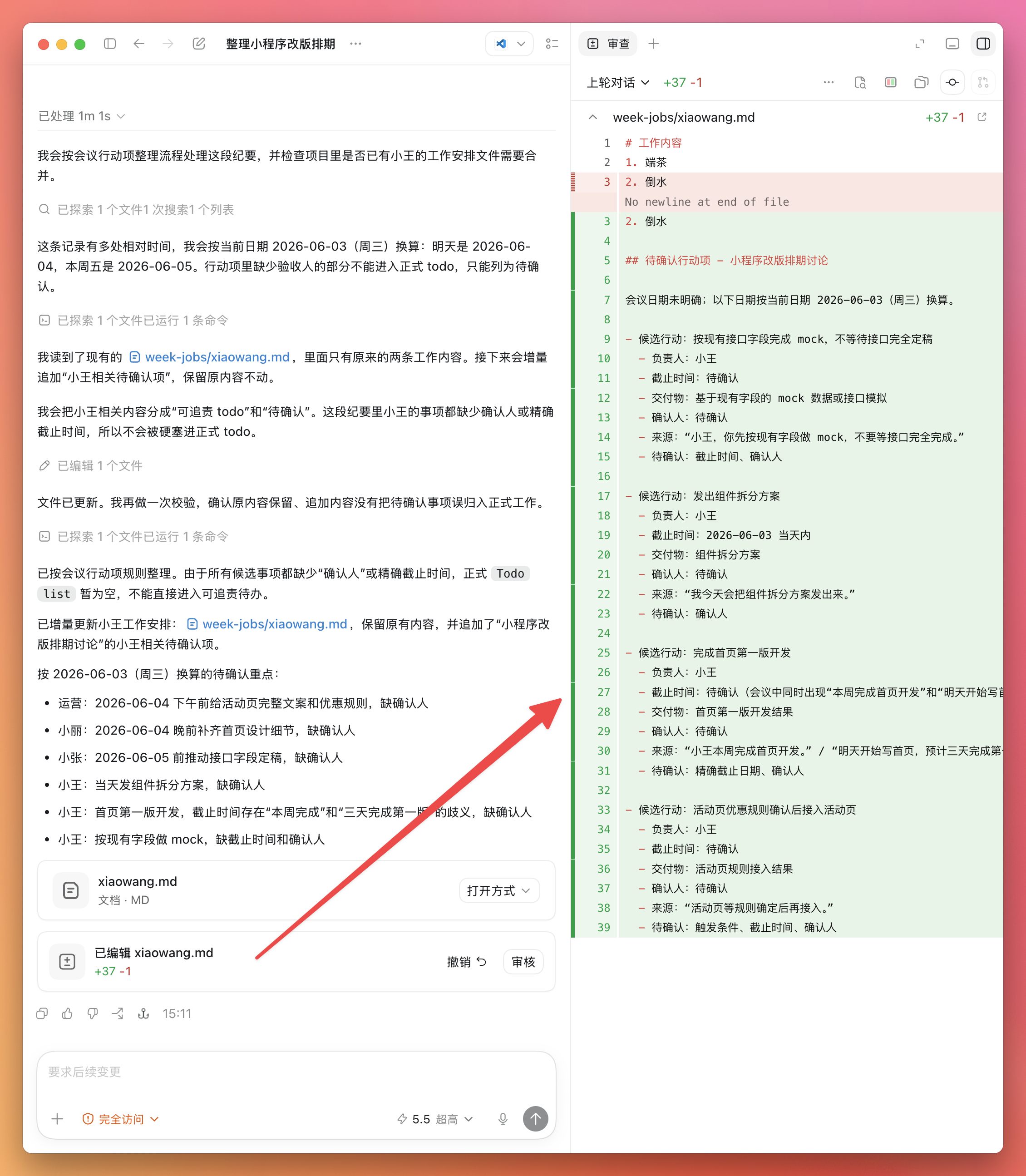
你不是学会了写一个文件。
你是把一段每次都要重新解释的工作方法,搬进了当前项目。
以前你每次都要说:
现在这些话进了 SKILL.md。下次在同一个项目里,Codex 不需要你从头讲一遍。
这就是 Skill 和普通 prompt 最大的区别。
prompt 像一句临时吩咐,说完就散。
Skill 像贴在项目墙上的规矩。对话换了,任务换了,只要项目还在,那张规矩还在。
最后只记这条路径:
skill-domain-framing 定高度prompt-review 立刻优化写 Skill 不是把话说得更漂亮。
是把话说到下次不用再说。
你可能以为,发布一个 Skill,就是打开终端,敲一串看起来很专业的命令。
但在这里,真正的玩法刚好反过来:你不自己搬箱子,你让 Codex 把箱子搬到公司库门口,再让它给你拿回一张 GitHub PR 小票。拿到它,才算这个 Skill 真正走上了“可以被别人看到、检查、合并”的发布流程。
开始之前,先确认三件事:
本章的目标很简单:
让 Codex 把本地 Skill 提交到公司库,拿到 GitHub PR 链接。
全程只和 Codex 对话。
不要自己敲命令。
这句话很重要。发布流程里最怕的不是慢,而是你手一快,绕过了检查点。就像寄快递,地址、收件人、包裹内容都还没核对,你已经把箱子扔上车了。车是开了,至于开到哪里,就不好说了。
发布到公司库,第一道门是 GitHub 登录。
你可以把 GitHub 理解成公司库大门上的电子锁。Codex 再能干,也得先确认这台机器有没有开门权限。不然它最多只能站在门口,礼貌地告诉你:我进不去。
复制下面这段话给 Codex:
检查当前机器是否具备发布 Skill 到公司库的 GitHub 登录状态。
要求:
1. 全程你来检查
2. 告诉我当前 GitHub 用户名
3. 如果已登录,输出:GitHub 登录已就绪
4. 如果未登录,引导我完成授权
5. 如果缺少发布所需工具,输出一段给环境负责人的求助话术你要看到的成功标准是:
GitHub 登录已就绪GitHub 用户名:[你的账号]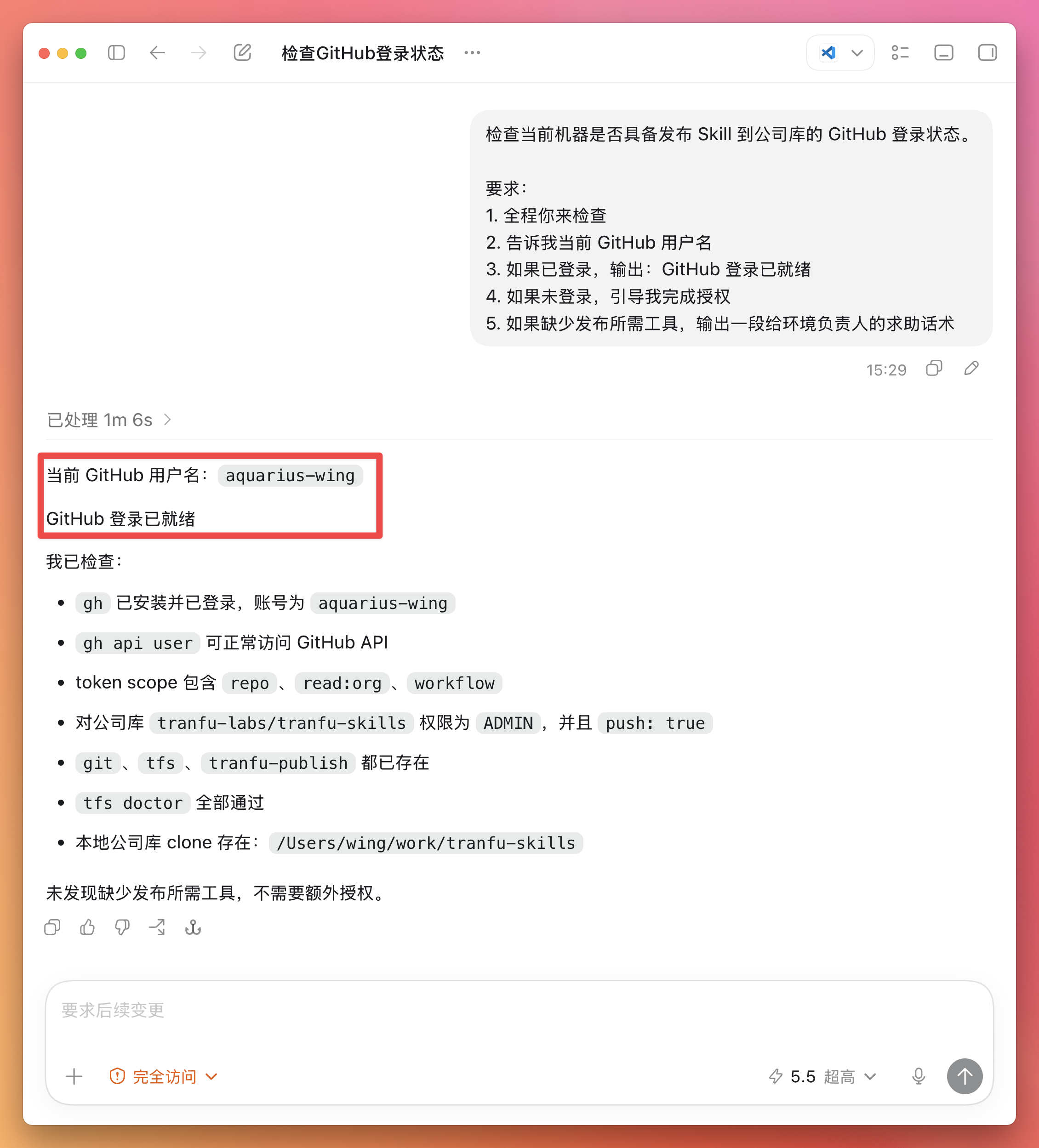
发布前先确认两件事:
示例话术可以这样判断:
| 类型 | 示例话术 | 判断 |
|---|---|---|
| 反例 | 我打算发布一个 meeting-saver skill,你可以访问得到它吗? |
访问不到时,要检查名字是否打错,或者之前的 Skill 是否不在这个文件夹。 |
| 正例 | 我打算发布一个 organize-meeting-actions skill,你可以访问得到它吗? |
organize-meeting-actions 是我们上一篇创建的,它可以正确访问得到。 |
反例截图:
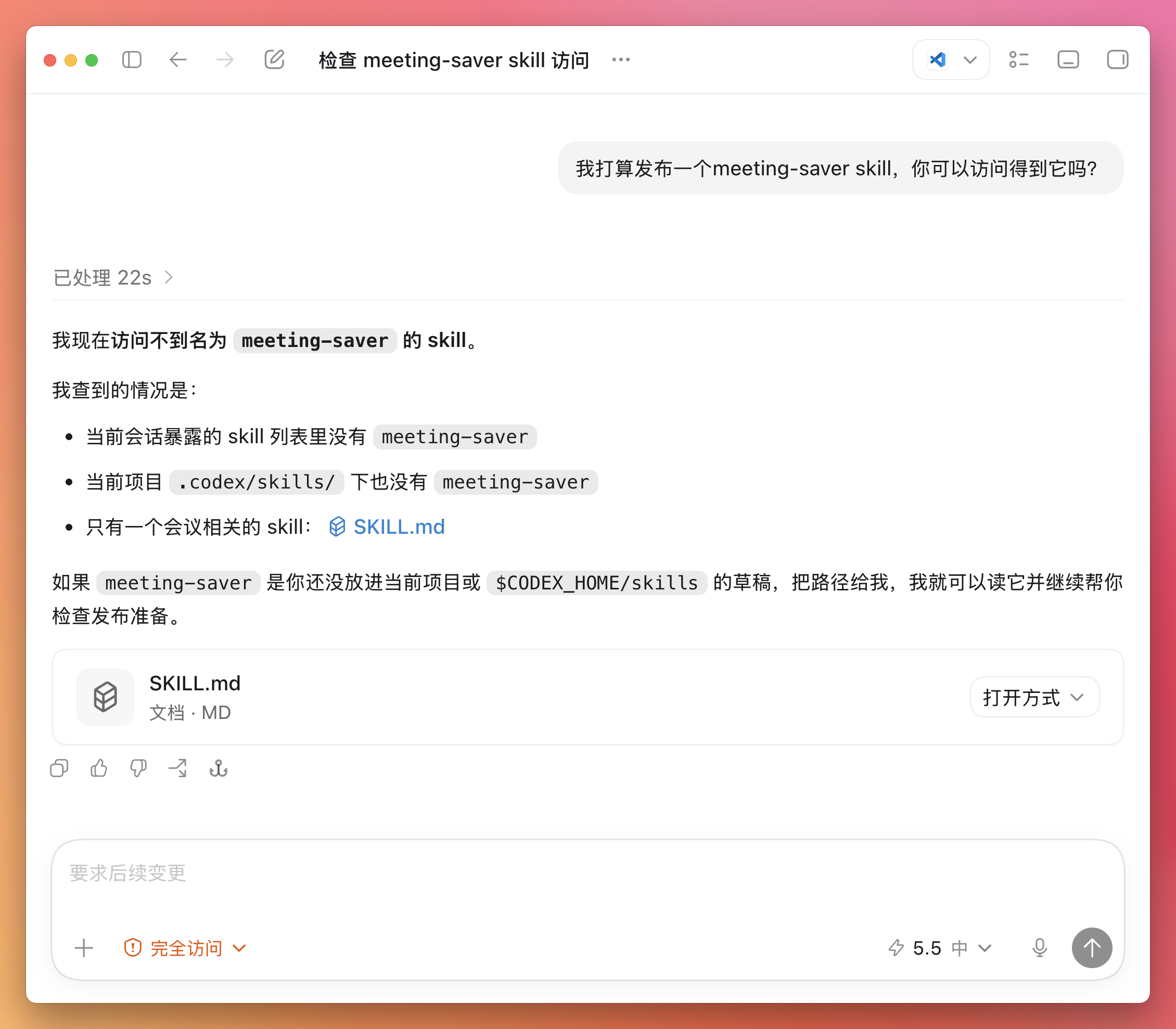
正例截图:
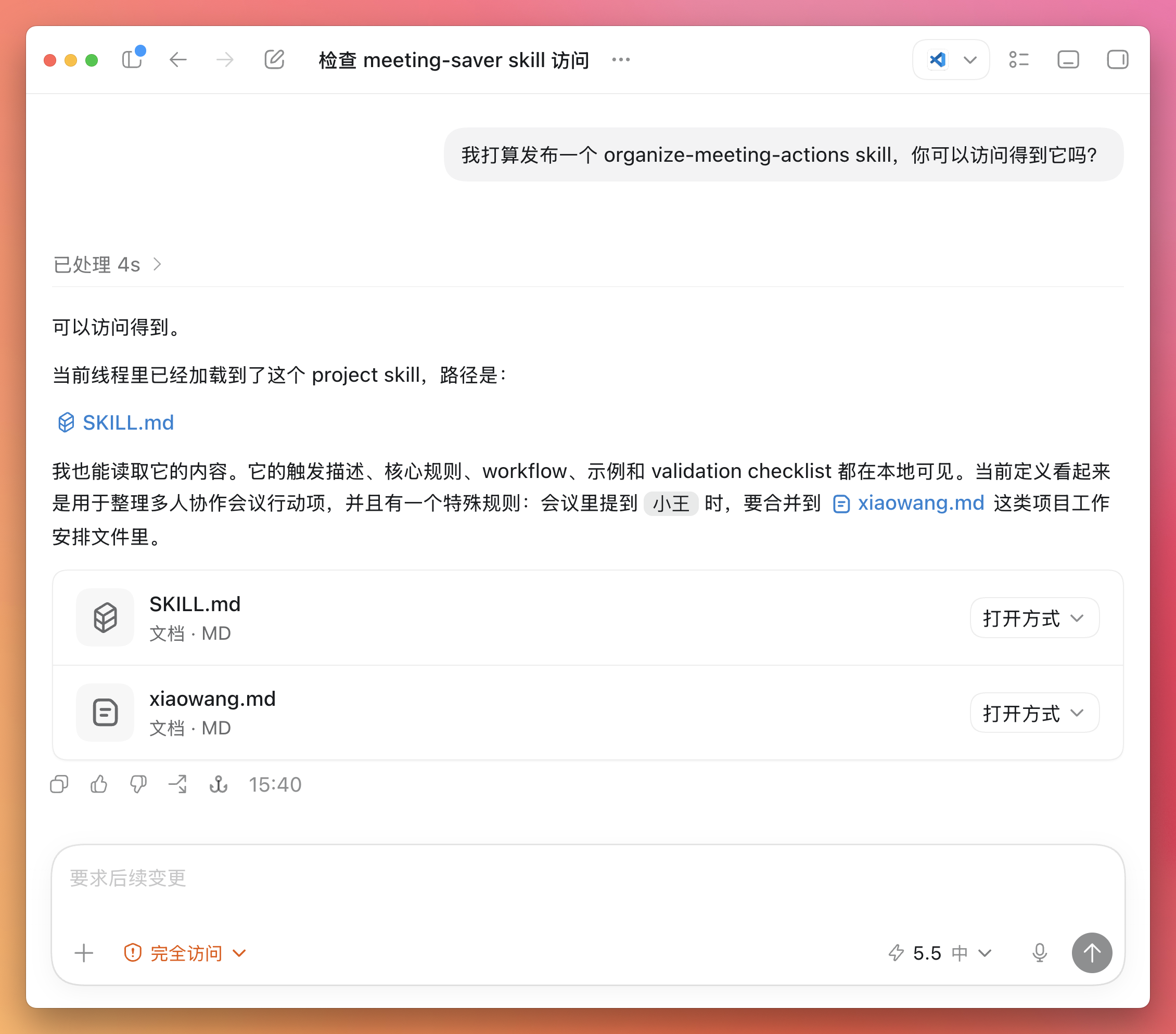
这里不需要执行什么终端命令,只需要告诉Codex一句话,它就会帮我们做:
把 organize-meeting-actions skill 分享到 Tranfu 库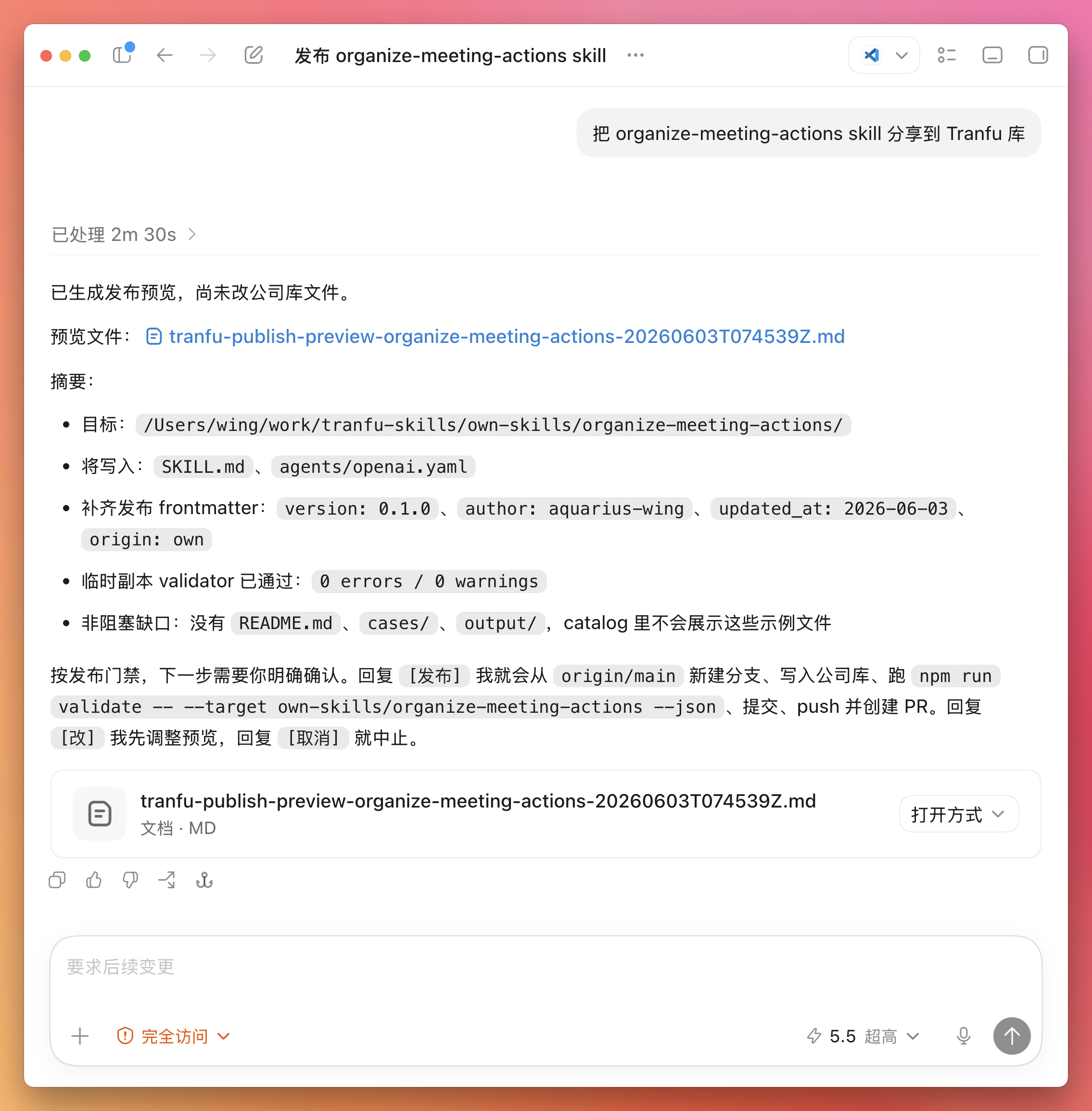
为什么这里会有一个临时文件?
| 项 | 说明 |
|---|---|
默认 SKILL.md |
只有 name 和 description 两个属性。 |
| Tranfu 库补充字段 | version、author、updated_at、origin。 |
| 临时文件作用 | 先把这些准备好,然后放到 Tranfu 库中。 |
接下来你需要干什么
跟它说一句发布即可。
跟AI说发布了之后,你会发现它返回了一个链接,
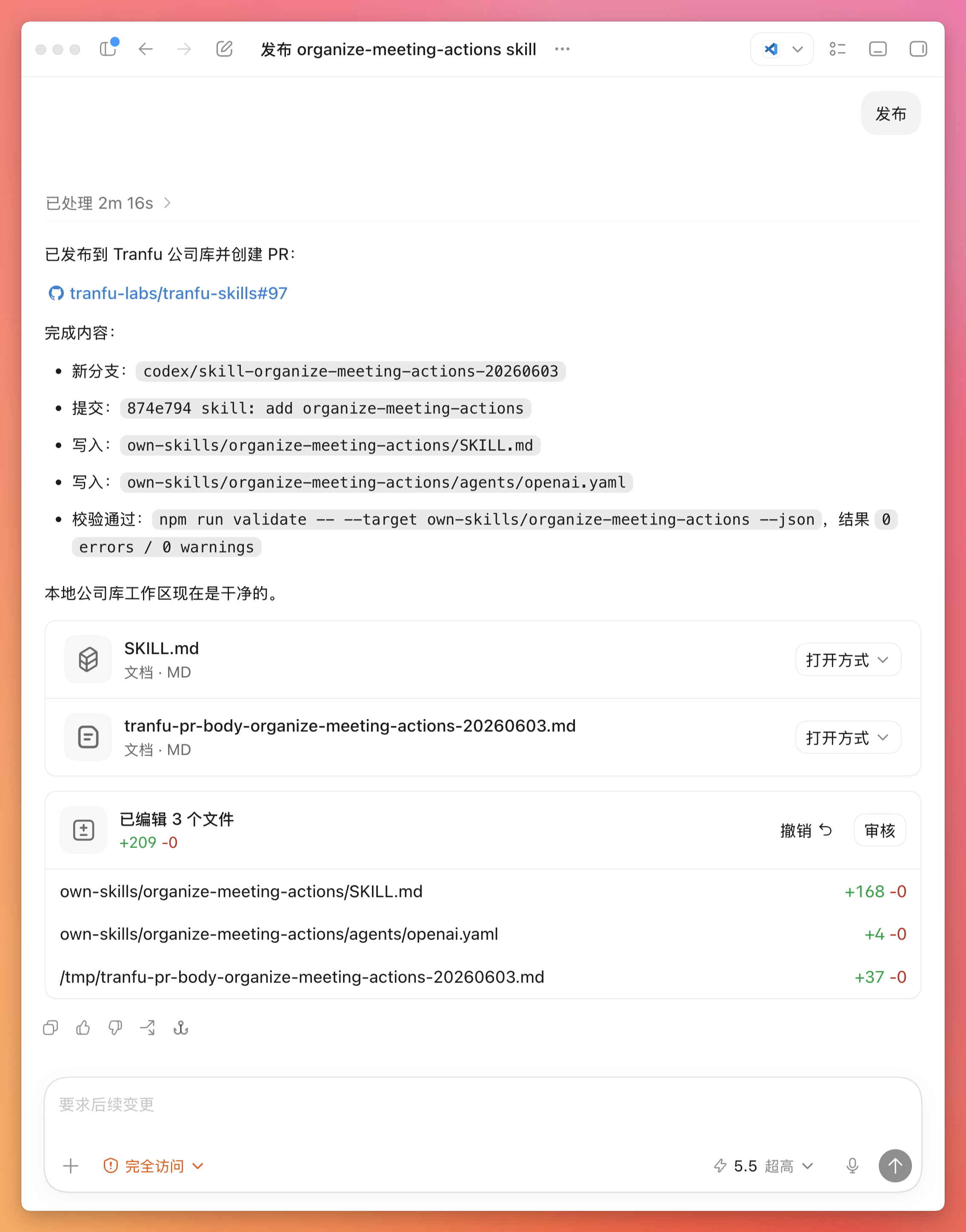
如果你是我们Tranfu公司的员工,还会收到一条通知
这里我解释一下里面最核心的概念:
| 概念 | 说明 |
|---|---|
| PR | tranfu-skills/pull/97,相当于是一个包含了你的发布的 Skill 的审批单,等待审核员进行审批。 |
等待审批完成之后,你会看到这样一条消息在Lark群中

到这里,你已经完成了第一次 Skill 发布。
这一章不再泛泛讲“Skill 要不要装很多”。
我们只盯着一个真实场景:
凡是涉及多人协作的会议,纪要必须在会后 24 小时内整理出行动项,每个行动项都要包含负责人、截止时间、交付物和确认人;没有负责人或截止时间的事项不能进入待办列表,内容是当提到小王的时候,就合并进他的工作安排中,工作安排通常在项目路径下的
week-jobs/xiaowang.md中。
这不是一个“会议纪要润色”需求。
它真正要做的是会议后事项跟进:
week-jobs/xiaowang.md。这类 Skill 特别适合拿来讲新手坑。
因为它看起来很小,实际边界很容易滑坡。你一不小心,就会把它写成“所有会议都管、所有待办都管、所有人的工作安排都管、所有项目管理都管”的超级 Skill。到最后,它既容易误触发,又容易改错文件,还会在每次触发时吃掉一大块上下文。
先把结论放前面:
会议后事项跟进 Skill 应该是项目级、强触发、轻正文、窄边界、可回归的工作单元。
为什么?
因为 Skill 不是常驻大脑增强包。Codex 通常先看到 Skill 的名字和 description,等任务相关时才加载完整 SKILL.md。一旦加载,正文就会进入上下文,和用户请求、对话历史、系统提示一起竞争空间。12
所以这一章用同一个会议后事项跟进 Skill,讲 8 个新手最常踩的坑。
会议后事项跟进 Skill 的第一件事不是写正文,而是先判断它应该装在哪里。
这个案例里有一条非常关键的线索:
工作安排通常在项目路径下的
week-jobs/xiaowang.md中
只要规则写到了项目路径、项目文件、项目成员,就优先放项目级 Skill。
比如你的项目是 /Users/wing/Develop/codex-tranfu-demo,那么这个 Skill 更适合放在 /Users/wing/Develop/codex-tranfu-demo/.codex/skills/organize-meeting-actions/SKILL.md。
它不适合直接装到用户级。
原因很简单:week-jobs/xiaowang.md 不是你所有项目都有的文件。小王也不是你所有项目里都有的人。把这条规则装到用户级,Codex 在别的项目里也可能误以为应该找这个文件,甚至创建一个不该出现的 week-jobs/xiaowang.md。
用户级更适合放通用方法,例如:
description。项目级才适合放这类规则:
week-jobs/xiaowang.md。判断方法很直接:
| 规则内容 | 推荐位置 |
|---|---|
| 所有项目都适用的 Skill 写作方法 | 用户级 |
| 所有会议都适用的行动项基本格式 | 可能用户级 |
| 绑定某个项目路径的工作安排规则 | 项目级 |
| 绑定某个成员文件的小王跟进规则 | 项目级 |
新手常犯的错,是把“我常用”误认为“所有项目都该用”。
会议后事项跟进 Skill 要反过来想:
只要它会读写当前项目里的具体文件,就先按项目级处理。
更准确地说,问题通常不在“你会不会拆出很多微 Skill”。
真实工作里,很少有人按程序步骤拆零件,把每个字段检查都做成独立 Skill。
更真实的问题是:你的工作台里已经有几个“看起来都能处理一点”的 Skill。
比如:
| Skill | 看起来能处理的部分 |
|---|---|
meeting-notes-summary |
把会议记录整理成正式纪要 |
project-todo-triage |
从项目材料里提取待办和风险 |
weekly-worklog-sync |
把成员事项合并进 week-jobs/ |
lark-meeting-cleanup |
清理飞书会议转写和聊天记录 |
follow-up-message-draft |
根据待办起草会后提醒话术 |
这些名字都合理,也都不是瞎拆。
问题是,用户只说一句:
把这次会议里小王的后续事项整理一下。
到底该用哪个?
Skill 不是越多越强。它更像按需调用的操作卡片。装很多 Skill,不代表它们每次都会一起帮忙;Skills 会按任务相关性自动使用,不需要你每次手动点名。3
这里要先判断“主 Skill”。
主 Skill 不看输入长什么样,而看最后不可省的结果是什么。
如果用户只是要:
把这段会议记录整理成纪要。
那主 Skill 可以是 meeting-notes-summary,甚至普通 prompt 就够。
如果用户要:
把会议里小王的后续事项整理出来,并合并进他的工作安排。
那主 Skill 就应该是项目级的:
organize-meeting-actions
因为这个任务的成败,不取决于纪要写得漂不漂亮,而取决于:
week-jobs/xiaowang.md。其它 Skill 可以作为辅助,但不应该抢主导。
比如飞书转写很乱,可以先让 lark-meeting-cleanup 清理材料;但真正决定行动项是否进入待办、是否写入 week-jobs/xiaowang.md 的,仍然应该是 organize-meeting-actions。
装之前先问这 5 个问题:
| 问题 | 通过才装 |
|---|---|
| 下周还会处理同类会议吗? | 会 |
| 是否每次都要检查行动项字段? | 是 |
| 是否每次都要更新小王工作安排? | 是 |
| 是否比临时 prompt 更稳定? | 是 |
| 是否能和已有会议、待办、周报 Skill 分清主次? | 能 |
这些就先别装:
description 写成“资料整理、待办管理、项目推进”。你可以让 Codex 先帮你清理 Skill 工具台:
帮我审查当前可用的 Skills。
只围绕“会议后事项跟进”判断:
1. 哪个 Skill 应该做主 Skill
2. 哪些 Skill 只能作为前置清理或辅助输出
3. 哪些 description 太泛,可能抢错任务
4. 哪些应该合并、改名、收窄或暂时不用
输出判断理由和建议动作,不要解释概念。一个好 Skill 不靠名字多,而靠主任务判断稳定。
会议后事项跟进就是这种任务:重复、规则明确、出错成本不低。
会议后事项跟进 Skill 最容易死在 description 上。
坏例子通常长这样:
description: 整理会议纪要、提取待办事项、优化会议内容。这句话看起来没错,但太宽。
它会带来三个问题。
week-jobs/xiaowang.md。description 是 Skill 的门牌。Codex 通常先看门牌,再决定要不要把完整 SKILL.md 读进来。门牌写宽了,路过也会进;门牌写窄了,该进的时候不进。4
这个案例的 description 要把四件事写清楚:
| 维度 | 要写清楚的内容 |
|---|---|
| 输入 | 多人协作会议的录音转写、聊天记录、零散会议笔记 |
| 输出 | 可跟进的行动项,以及小王工作安排文件的合并更新 |
| 触发 | 用户要求整理会议后事项、会后待办、小王相关会议任务 |
| 排除 | 普通摘要、文章润色、个人备忘、替负责人拍板 |
可以这样写:
description: 整理多人协作会议的录音转写、聊天记录和零散笔记,提取会后行动项,并检查每个行动项是否包含负责人、截止时间、交付物和确认人;没有负责人或截止时间的事项不得进入待办列表。当会议内容提到小王,或用户要求同步小王的会议后事项时,把属于小王的行动项合并进项目内 week-jobs/xiaowang.md。用于会议后事项跟进、会后待办整理和小王工作安排同步。不要用于普通会议摘要、文章润色、个人备忘、战略判断、绩效评价,或替负责人确认未拍板事项。写完以后不要凭感觉说“应该可以”。直接做触发测试。
应该触发:
week-jobs/xiaowang.md。不应该触发:
可复制:
请帮我优化这个会议后事项跟进 Skill 的 description。
要求:
1. 保留“多人协作会议 -> 行动项 -> 小王工作安排文件”的边界
2. 明确负责人、截止时间、交付物、确认人四个字段
3. 明确没有负责人或截止时间不能进入待办列表
4. 补上 8 条应该触发的真实用户说法
5. 补上 8 条不应该触发的相邻场景
6. 只改 description,不改正文
Skill 路径:
[粘贴 SKILL.md 路径]如果会议后事项 Skill 经常误触发,先别急着怪模型。多数时候,是 description 把“会议摘要”“待办管理”“项目管理”这些相邻任务也写进来了。
会议后事项跟进 Skill 一旦触发,完整 SKILL.md 会进入上下文。
这就是为什么它不能写成一份“会议管理百科”。
上下文窗口是公共资源。Skill 会和系统提示、对话历史、其他 Skill 元数据、用户请求一起竞争上下文。即使 SKILL.md 写得有道理,只要它太长,一旦加载,每个 token 都会和其它信息抢位置。1
这个案例的主文件应该很短。
应该放进 SKILL.md 的,是执行时必须马上知道的规则:
week-jobs/xiaowang.md。不应该放进主文件的,是低频背景:
如果确实需要长资料,拆到 references/:
| Reference | 放什么 |
|---|---|
references/action-item-format.md |
行动项字段和示例 |
references/team-members.md |
团队成员角色说明 |
references/follow-up-examples.md |
历史会议样例 |
但只拆出去还不够。你还要写清楚什么时候读。
这样写才有用:
references/action-item-format.md。references/team-members.md。references/follow-up-examples.md。references/ 下的长样例。别只写:
更多资料见
references/。
这句话对 Codex 没什么帮助。它知道有仓库,但不知道该翻哪一箱。
固定检查可以脚本化。
比如这个 Skill 的稳定校验可以放到 scripts/:
week-jobs/xiaowang.md 里的旧任务。还有一类内容既不是 references/,也不是 scripts/。
它是关键任务流程里的显式动作。
比如会议后事项跟进 Skill 如果只写:
这不够。
这些话太软,Codex 很可能直接往下做。关键流程缺失时,要把 Codex 里更接近的动作写明白。Codex 官方建议复杂或模糊任务先 plan,也可以让 Codex 先 interview 你;subagents 也不会自动触发,必须明确要求 spawn / delegate。56
在这个 Skill 里可以这样写:
| 缺的不是规则,而是流程动作 | 在 Codex 里应该写成 |
|---|---|
| 会议目标、确认人、目标文件不清楚 | 先进入 Plan mode,或先 interview 用户,问清缺失字段再执行 |
| 步骤多,容易漏读旧文件或漏验证 | 维护执行计划,逐步更新 update_plan:提取、过滤、读旧文件、合并、验证7 |
| 会议材料很长,提取行动项会污染主上下文 | 显式 spawn 一个 subagent,只负责从材料里提取候选行动项并返回摘要 |
| 需要实际落地到项目文件 | 明确读 week-jobs/xiaowang.md、合并编辑、再检查 diff |
注意,这里不是把 Claude Code 的 AskUserQuestion、TaskCreate 这些名字照搬进 Codex Skill。
更稳的写法是写 Codex 能直接执行或理解的动作:
update_plan,至少包含:提取行动项、过滤缺字段事项、读取小王旧工作安排、合并新事项、检查 diff。可复制:
请压缩这个会议后事项跟进 Skill。
目标:
1. 删除会议管理科普和 Agent 已经知道的通用解释
2. 保留触发边界、行动项字段、待确认规则、文件更新规则
3. 把低频样例拆到 references/
4. 把可机械检查的字段完整性规则放到 scripts/
5. 在 SKILL.md 里写清每个 reference 和 script 什么时候使用
6. 补上关键流程动作:什么时候 Plan/interview,什么时候 update_plan,什么时候 spawn subagent,什么时候读写文件
7. 不改变“多人协作会议 -> 行动项 -> 小王工作安排”的任务边界
Skill 路径:
[粘贴 SKILL.md 路径]会议后事项跟进 Skill 费不费 token,不只看它有没有用,还看它有没有把低频资料全带上桌。
这个 Skill 应该写大一点,还是拆小一点?
不要按字数判断。
按工作单元判断。
更稳的方法是问三件事:
对会议后事项跟进来说:
| 维度 | 会议后事项跟进的判断 |
|---|---|
| 输入 | 多人协作会议材料 |
| 产出 | 结构化行动项,以及小王工作安排文件更新 |
| 失败标准 | 漏掉行动项、编造负责人、缺少截止时间、覆盖旧任务、误改无关文件 |
这些可以放在同一个 Skill 里:
| 候选范围 | 判断 |
|---|---|
| 会议录音、会议聊天记录、零散会议笔记 -> 行动项 | 可以合 |
| 行动项字段完整性检查 | 可以合 |
小王相关行动项 -> week-jobs/xiaowang.md |
可以合 |
| 读取旧工作安排并合并新任务 | 可以合 |
这些不要顺手塞进去。不是因为它们不重要,而是它们更像另一个主任务:
| 候选范围 | 判断 |
|---|---|
把所有成员的事项统一归档到 week-jobs/ |
可能是 weekly-worklog-sync |
| 从会议结论更新项目排期表 | 可能是项目排期维护 Skill |
| 给参会人起草会后提醒消息 | 可能是会后沟通 Skill |
| 把会议记录改写成正式纪要 | 可能是会议纪要 Skill |
| 根据会议内容生成周报 | 可能是周报 Skill |
为什么“写入小王文件”可以合?
因为它不是另一个任务,而是这个会议后事项跟进流程的落地动作。会议里提到小王,如果不更新他的工作安排,这个 Skill 的目标就没完成。
为什么“所有成员事项归档”不要直接合?
因为输入、输出、失败标准都变了。它不再是处理一场会议里的小王事项,而是在维护一套成员工作台账。那可以是另一个 Skill,也可以是后续工作流,但不该悄悄塞进当前 Skill。
可复制:
帮我判断这个会议后事项跟进 Skill 应该拆还是合。
候选范围:
1. 整理多人协作会议行动项
2. 检查负责人、截止时间、交付物、确认人
3. 小王相关事项写入 week-jobs/xiaowang.md
4. 把所有成员事项统一归档到 week-jobs/
5. 根据会议内容起草会后提醒消息
只按这 3 个标准判断:
1. 输入是不是同一类
2. 产出是不是同一种
3. 失败标准是不是同一个
最后输出:
1. 保留一个 / 拆成几个 / 合并到已有 Skill
2. 推荐 Skill 名称
3. 推荐 description 边界
4. 不要覆盖的相邻场景判断拆还是合,不要问“它能不能顺手也做”。会议后事项跟进 Skill 的边界,通常就是被“顺手把所有人的安排也同步一下”撑爆的。
prompt 管这一次。
Skill 管以后每一次。
会议后事项跟进特别适合说明这个区别。
如果你只是在某一次会议后说:
这些是 prompt。
它们只影响这一次,不应该写进 Skill。
但下面这些是每次都要遵守的规则:
week-jobs/xiaowang.md。这些应该写进 Skill。
资料里对这个区别说得很清楚:prompt 是对话级的一次性指令;Skill 是按需加载的可复用专业能力。Skills 适合团队流程、品牌规范、会议纪要格式、数据分析流程这类可重复工作。Custom instructions 更广泛地应用,Skills 只在相关任务加载。82
简单判断:
| 内容 | 放哪里 |
|---|---|
| 这次纪要语气轻松一点 | prompt |
| 这次只看技术事项 | prompt |
| 先输出草稿,不写文件 | prompt |
| 行动项必须有负责人和截止时间 | Skill |
小王事项合并进 week-jobs/xiaowang.md |
Skill |
| 旧任务不能被覆盖 | Skill |
| 长样例和历史写法 | references/ |
| 字段完整性和文件差异检查 | scripts/ |
千万别把 Skill 写成“我每次都可能想说的话合集”。
会议后事项跟进 Skill 只应该固定这几件事:
可复制:
请判断下面这些要求应该放进会议后事项跟进 Skill,还是留在本次 prompt。
规则列表:
1. [规则 1]
2. [规则 2]
3. [规则 3]
判断标准:
1. 只对这次会议有效 -> prompt
2. 每次会议后都要遵守 -> Skill
3. 很长但低频 -> references/
4. 可自动校验 -> scripts/
输出表格,不要展开解释。一句话:你只是今天想这么做,用 prompt;你不想以后每次都重新解释,就写进 Skill。
会议后事项跟进 Skill 发布后,第一次跑歪很正常。
但不要整份重写。
要先分类。
同样是跑歪,原因可能完全不同:
| 现象 | 先改哪里 |
|---|---|
| 用户说“整理小王会后事项”但 Skill 没触发 | description 太窄 |
| 用户只是要会议摘要,Skill 却触发 | description 太宽 |
| 输出了没有截止时间的待办 | workflow 或 gotchas 缺规则 |
| 把“待确认”写进正式待办 | 输出模板不清 |
覆盖了 week-jobs/xiaowang.md 旧内容 |
文件更新步骤缺读旧文件 |
| 把小张的事项写给小王 | 负责人归属规则不清 |
| 每次都手动检查字段 | 应该补 scripts/ |
| 关键字段缺失时还继续写文件 | 应该显式要求 Plan mode 或 interview 用户 |
| 经常漏掉读取旧文件、合并、验证这几个步骤 | 应该显式要求维护 update_plan |
| 会议材料太长,主线程里塞满转写细节 | 应该明确 spawn subagent 做候选行动项提取 |
第一版 Skill 本来就常常要靠真实任务继续修改。更重要的是,你要看执行轨迹,不只看最终结果。如果 Agent 浪费步骤,常见原因是规则太泛、不适用,或者给了太多同级选项。触发问题还要用 should-trigger / should-not-trigger 查询集反复测。94
修改时记住三条:
description 改到过拟合。再加一条更关键的:
比如失败现象是:
会议里说“小王先按现有字段做 mock”,但没有明确截止时间。Codex 把它写进了正式待办。
这时候不要重写整个 Skill。
只补一条 gotcha:
如果行动项缺少负责人或截止时间,必须放入“待确认”,不得写入正式待办,也不得写入
week-jobs/xiaowang.md。
再用同一条会议材料回归。
如果失败现象是:
会议材料很长,Codex 在主线程里贴了大量转写细节,最后漏掉了小王的两条任务。
也不要只补一句“仔细阅读会议材料”。
要补成可执行的子 Agent 规则:
当会议材料很长、包含多段转写或多场会议时,spawn 一个 subagent。该 subagent 只做候选行动项提取,返回负责人、截止时间、交付物、确认人和原文依据。主 agent 不接收原始长转写,只接收摘要后再判断哪些事项能进入正式待办和
week-jobs/xiaowang.md。
如果失败现象是:
Codex 提取了行动项,但忘了先读取
week-jobs/xiaowang.md,直接覆盖了旧内容。
要补成计划规则:
执行时必须维护
update_plan,且不能跳过这 5 步:提取候选行动项、过滤缺负责人或截止时间的事项、读取week-jobs/xiaowang.md旧内容、合并新事项、检查 diff 确认旧事项未被删除。
可复制:
这个会议后事项跟进 Skill 发布后跑歪了。
失败现象:
[写清楚哪里错]
真实会议材料:
[粘贴触发请求和会议内容]
请先分类:
1. 触发问题
2. 执行步骤问题
3. 输出格式问题
4. 缺少 gotcha
5. 应该脚本化
6. 是否缺少 Plan/interview/update_plan/文件读写这类显式流程动作
7. 是否应该把过长子任务交给 subagent
然后只做最小修改。
不要重写整份 SKILL.md。
改完后,用同一条会议材料再跑一次。会议后事项跟进 Skill 的迭代,不靠豪华重构。它靠一次抓住一个偏差。
公司库里的 Skill 也不能闭眼装。
会议后事项跟进 Skill 尤其要小心,因为它通常会读写项目文件:
week-jobs/xiaowang.md。week-jobs/xiaowang.md。references/ 里的团队成员说明。scripts/ 做字段检查。资料里说得很直接:只从可信来源安装 Skill;安装不太可信的 Skill 前,要检查其中的文件、依赖、资源和外部网络访问。Skill 的主要风险包括 prompt injection 和 data exfiltration。3
翻译成人话就是:
它可能诱导 Agent 做不该做的事,也可能把不该出去的数据带出去。
安装这个 Skill 前,至少看 6 件事:
SKILL.md 的任务边界是不是只处理会议后事项跟进。description 有没有泛化到资料整理、项目管理、绩效评价。allowed-tools / disallowed-tools 有没有给过大权限。scripts/ 是否会读写 week-jobs/ 之外的路径。优先安装这些:
先别安装这些:
description 写成“整理会议、同步待办、推进项目、跟踪成员”。week-jobs/ 和会议材料。可复制:
帮我审查这个公司库里的会议后事项跟进 Skill 是否适合安装到真实项目。
检查:
1. SKILL.md 是否只覆盖多人协作会议后的行动项跟进
2. description 是否太泛,是否会误触发普通摘要、周报、项目管理
3. allowed-tools / disallowed-tools 是否合理
4. scripts/ 是否只做本地字段检查,是否读写敏感文件
5. 是否会访问外部网络或上传会议内容
6. 是否明确保护 week-jobs/xiaowang.md 的旧内容
7. 是否和我已有会议纪要或待办 Skill 重叠
输出:
1. 建议安装 / 先不安装 / 只在练习项目试用
2. 风险点
3. 安装前要问维护者的问题公司库不是自动可信区。会议内容和成员工作安排都可能敏感,越是会读写项目文件的 Skill,越要先看清楚它能碰哪里。
把这张表贴到每次审查前面。
| 问题 | 判断标准 |
|---|---|
| 1. 装到哪里? | 写到项目路径和小王文件,就放项目级 |
| 2. 怎么判断主 Skill? | 看最后不可省的结果,不看输入材料像什么 |
| 3. 为什么误触发? | 多半是 description 把会议摘要、待办管理、项目管理都写进来了 |
| 4. 为什么更费 Token? | SKILL.md 太重,触发后抢上下文 |
| 5. 写大还是拆小? | 输入、产出、失败标准一致就合,否则拆 |
| 6. Skill 和 prompt 怎么分工? | 一次性偏好放 prompt,重复流程放 Skill |
| 7. 发布后不好用怎么办? | 分类问题;流程缺失补显式动作,长子任务指定 subagent |
| 8. 公司库能不能直接装? | 先审来源、权限、脚本、联网和文件读写范围 |
最后给 Codex 的总检查 prompt:
请按“会议后事项跟进 Skill 避坑清单”审查这个 Skill。
检查 8 件事:
1. 是否应该装到项目级
2. 是否值得创建或安装
3. description 是否容易误触发
4. SKILL.md 是否太重
5. 范围应该拆还是合
6. 哪些内容应该留在 prompt
7. 是否缺少 Plan/interview/update_plan/文件读写/subagent 这些显式流程动作
8. 是否适合从公司库安装到真实项目
要求:
1. 先给结论:保留 / 修改 / 不建议安装
2. 每条只写问题和最小修改建议
3. 不要重写整份 Skill
Skill 路径:
[粘贴 SKILL.md 路径]会议后事项跟进 Skill 真正厉害的地方,不是把“会议纪要”四个字写进一个新文件。
它厉害在:把会后跟进里最容易漏、最容易编、最容易改错文件的规则固定下来。
下次你再丢一段会议记录,Codex 不应该只是写一段漂亮摘要。
它应该知道:
这才是 Skill 和普通 prompt 的区别。
prompt 解决这一次。
Skill 固定以后每一次。
这篇只用了能落到操作上的一手资料:



